
티스토리 뷰
개요
앞선 포스팅에서 마이크로서비스 분산DB 환경에서 고려되어야 할 사항에 대해 살펴보았다. 자세한 내용은 아래 포스팅을 참고하기 바란다.
- 마이크로서비스 Schema 분리 설계 (테이블 분리, 외래키 참조관계, 조인, 데이터 정합성 보장) : https://waspro.tistory.com/730
- 마이크로서비스 데이터베이스 분리 설계 : https://waspro.tistory.com/729
- 마이크로서비스 분산DB 설계 (분산DB 데이터 분할, 동기화 설계) : https://waspro.tistory.com/726
- 마이크로서비스 분산DB 설계 (분산DB 조회 설계) : https://waspro.tistory.com/724
- 마이크로서비스 아키텍처의 기준과 DB 분리 : https://waspro.tistory.com/718
이번 포스팅에서는 분산 환경에서의 트랜잭션 관리 방법에 대해 알아보자. 단일 DB 환경에서는 데이터의 안전성과 일관성을 보장하는 데이터베이스에 의존하여 개발과 성능 보장에 포커싱을 맞춰 접근할 수 있다. 그러나 데이터베이스 간에 데이터를 분할할 경우 데이터베이스 트랜잭션을 사용하여 상태 변화를 ACID 원칙에 따라 보장할 수 없어 그 이점이 사라진다. 이를 해결하기 위한 방안에 대해 살펴보도록 하자.
먼저 이 문제를 해결하는 방법에 대해 살펴보기 전 데이터베이스 트랜잭션이 제공하는 내용을 간략하게 살펴보도록 하자.
ACID Transaction
일반적으로 데이터베이스 트랜잭션에 대해 이야기할 때 ACID 트랜잭션에 대해 이야기한다. ACID는 데이터 저장소의 내구성과 일관성을 보장하기 위해 신뢰할 수 있는 시스템으로 이어지는 데이터베이스 트랜잭션의 주요 속성을 설명하는 약어이다. ACID 는 원자성(Atomicity), 일관성(Consistency), 격리(Isolation) 및 내구성( Durability)을 나타내며 이러한 속성이 제공하는 것은 다음과 같다.
- 원자성(Atomicity) : 트랜잭션 내에서 완료된 모든 작업이 모두 완료되거나 모두 실패하도록 한다. 어떤 이유로 인해 변경하려는 변경 사항이 실패하면 전체 작업이 중단되고 변경 사항이 전혀 적용되지 않은 것처럼 동작한다.
- 일관성(Consistency) : 데이터베이스가 변경되면 유효하고 일관된 상태로 유지되도록 보장한다.
- 격리(Isolation) : 여러 트랜잭션이 간섭 없이 동시에 작동할 수 있다. 이것은 한 트랜잭션 동안 이루어진 모든 중간 상태 변경이 다른 트랜잭션에 표시되지 않도록 함으로써 달성된다.
- 내구성(Durability) : 거래가 완료되면 시스템 오류가 발생하더라도 데이터가 손실되지 않도록 보장한다.
이 ACID 속성 중 트랜잭션 경계를 나눌 때 가장 먼저 부딪히는 문제가 원자성이다. 지금부터 이에 대해 자세히 살펴보도록 하자.
마이크로서비스 그리고 분산 트랜잭션
데이터베이스를 분리할 때 ACID 스타일 트랜잭션을 계속 사용할 수 있지만 이러한 트랜잭션의 범위와 유용성이 감소한다는 점을 기억하자.

고객서비스에 CUSTID 0001인 고객이 은행 계좌를 탈퇴하려고 한다. 이때 고객 서비스의 CUST 테이블에 해당 CUSTID를 갖는 Row를 삭제한 후 이체 서비스에 UserID가 0001인 사용자의 정보를 모두 삭제해야 한다고 가정해 보자. 단일 데이터베이스에서는 단일 ACID 데이터베이스 트랜잭션 범위 내에서 이 작업이 수행된다. 이는 두 테이블의 Row가 모두 반영되거나 반영되지 않는다.
위 동작은 정확히 같은 변경을 하고 있지만, 이제 각 변경은 다른 데이터베이스에서 이루어지고 이것은 고려해야 할 두 개의 트랜잭션이 있음을 의미하며, 각각은 서로 독립적으로 작동하거나 실패할 수 있다는 의미이다.
물론 두 서비스에서 동작하는 CUD 동작을 하나의 트랜잭션으로 묶어 처리할 수 있지만, 궁극적으로 결합도를 낮추는 마이크로서비스를 구현하는 방식과는 맞지 않으며, 이렇게 구현할 경우 굳이 서비스를 구분하지 않고 하나의 서비스로 구성하는 것이 더 낫다고 볼 수 있다. 또한, 어플리케이션 레벨에서 여러 트랜잭션을 묶어 처리하기 때문에 성능 저하 현상이 발생할 수 있다. 오히려 이와 같은 경우 비즈니스 처리 순서를 재정렬하는 것도 하나의 방식이 될 것이다. 그러나 근본적으로 이 작업을 두 개의 개별 데이터베이스 트랜잭션으로 분해함으로써 전체 작업의 보장된 원자성을 상실했다는 사실을 기억해야 한다.
이러한 원자성 부족은 특히 이전에 이 속성에 의존했던 시스템을 마이그레이션하는 경우 심각한 문제를 일으킬 수 있다. 이 시점에서 사람들은 한 번에 여러 서비스에 대한 변경 사항을 관리할 수 있는 솔루션 또는 개발 방식에 대해 고려하기 시작한다. 이때 고려되는 분산 트랜잭션 관리 방안으로 대표적인 방식인 2Phase Commit과 Saga Pattern에 대해 알아보도록 하자.
2Phase Commit
2Phase Commit 알고리즘(이하 2PC)은 분산 시스템에서 트랜잭션을 변경할 수 있는 기능을 제공하는 방식이다. 이때 2PC제한 사항이 존재한다.
2PC는 투표 단계와 커밋 단계라는 두 단계로 나뉜다. 투표 단계에서는 Coordinator가 거래의 일부가 될 모든 대상 서비스에 직접 연결하여 상태 변경이 가능한지 확인 요청한다.
[투표 단계]
- 1. Coordinator는 고객서비스의 CUSTID 0001 삭제 요청과 이체서비스의 UserID가 0001인 행 삭제 요청을 보낸다.
- 2. 고객서비스와 이체서비스에서 상태 변경이 가능여부에 대해 투표하고 해당 Row에 lock을 잡는다.
- 2-1. 투표 결과 모두 가능하다고 하면 각 서비스에서 상태를 변경하고 다음 단계로 넘어간다.
- 2-2. 하나라도 상태 변경이 불가능하다고 투표하면 트랜잭션은 중단된다.

이때 각 서비스가 변경 가능 여부에 대해 투표한 즉시 변경사항이 적용되지 않는다는 점을 기억하자. 투표에 동의한 서비스의 변경이 나중에 이루어질 수 있도록 하기 위해 반영 결과에 대해 Lock을 걸어둔다.
만약 이체 서비스가 투표에 동의하지 않았을 경우, 고객 서비스에 롤백 메시지를 보내야 한다. 모든 서비스가 투표에 동의하면 다음과 같이 Commit 단계로 이동한다. 여기서 변경사항이 실제로 적용되고 관련 Lock이 해제된다.
[Commit 단계]
- 1. Coordinator는 Commit 메시지를 각 서비스로 전달한다.
- 2. 고객서비스는 CUSTID 0001인 Row를 삭제하고, 이체서비스는 UserID가 0001인 Row를 모두 삭제한다.
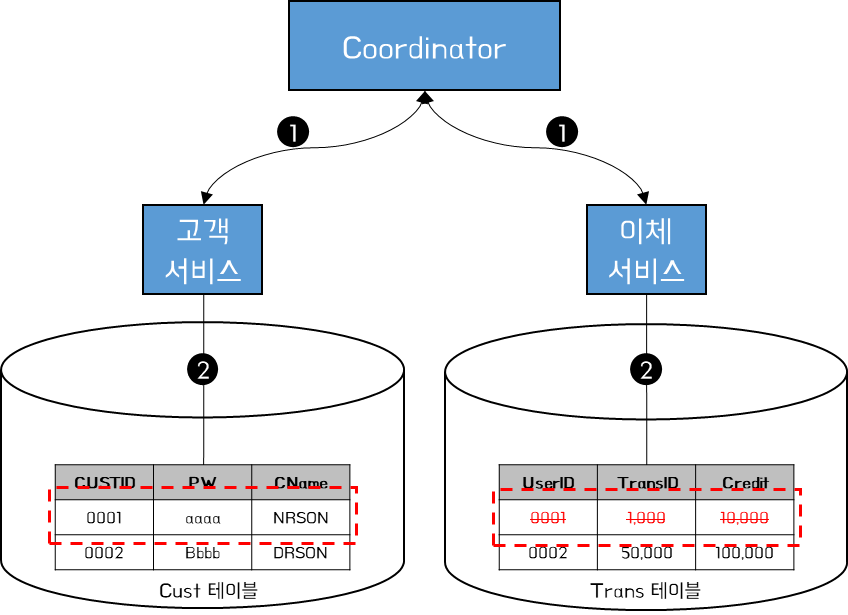
Commit 단계에서는 모든 서비스에 정확히 동시에 적용된다고 보장할 수 없다는 점에 유의해야 한다. Coordinator는 모든 서비스에게 커밋 요청을 보내야 하며 해당 메시지는 다른 시간에 도착하여 처리될 수 있다. 이는 타이밍 이슈로 인해 고객서비스에 대한 변경 사항을 볼 수 있지만 이체서비스에 대한 변경 사항은 아직 반영되지 않을 수 있다는 점이다.
2PC는 서비스가 증가할수록 시스템의 대기 시간이 길어지며, 이는 응답시간의 증가를 초래한다. 특히 Lock을 잡아야 하는 Row의 범위가 크거나 트랜잭션 기간이 긴 경우 시스템에 엄청난 대기시간을 발생시키게 된다. 이러한 이유로 2PC는 일반적으로 수명이 매우 짧은 작업에만 사용하는 것을 권장한다.
결론
지금까지 마이크로서비스의 분산 트랜잭션 처리 방식과 2PC에 대해 알아 보았다. 위에 자세히 설명했듯이 마이크로서비스 전체에서 상태 변경을 조정하기 위해 2PC와 같은 분산 트랜잭션을 사용하지 않는 것이 좋다. 2PC는 결국 Coordinator를 기반으로 강력한 결합을 유도하고, 데이터에 직접적인 Lock을 잡고 처리하기 때문에 서비스간 영향도와 궁극적으로 성능에 지대한 영향을 줄 수 있기 때문이다.
그렇다면 결국 분산 트랜잭션 환경에서 마이크로서비스의 트랜잭션 관리 방법은 무엇이 있을까?
두가지를 고민해 볼 수 있을 것이다. 바로 데이터를 분리하지 않는 방법과 Saga Pattern을 적용하는 방법이다. 데이터를 분리하지 않는 방법은 결국 앞서 누누이 이야기 했던 오리진으로의 회귀를 의미한다. 결국 이와 같은 어려움에 직면하여 다시 모놀리스 아키텍처를 선택하게 되는 많은 프로젝트의 사례가 이를 증명하고 있다. 데이터베이스가 보장하는 ACID를 명확히 보장하기 위해서는 단일 데이터베이스로 데이터를 관리하는 것이 가장 좋은 방법이다.
그러나 마이크로서비스의 최종 목적지인 데이터의 분리를 위해서는 결과적으로 이와 같은 문제를 감수해야 한다. Coordinator의 관리 방식에서 벗어나는 방법, 서비스간 Lock을 피하는 방법, 대기시간을 줄일 수 있는 방법에 대해 지속적인 고민을 해야 하며, 대안으로 Saga Pattern을 고려할 수 있다.
다음 포스팅에서는 Saga Pattern을 적용한 분산트랜잭션 관리 방안에 대해 알아보도록 하자.
'③ 클라우드 > ⓜ MSA' 카테고리의 다른 글
| 마이크로서비스로의 점진적 전환 시 고려사항 (6) | 2021.12.04 |
|---|---|
| 마이크로서비스 분산 트랜잭션 관리 (Saga Pattern) (5) | 2021.11.23 |
| 마이크로서비스 Schema 분리 설계 (테이블 분리, 외래키 참조관계, 조인, 데이터 정합성 보장) (0) | 2021.11.22 |
| 마이크로서비스 데이터베이스 분리 설계 (0) | 2021.11.22 |
| 마이크로서비스 분산DB 데이터 분할, 동기화 설계 (0) | 2021.11.21 |
- Total
- Today
- Yesterday
- webtob
- nodejs
- TA
- Da
- wildfly
- 마이크로서비스
- SWA
- apache
- openstack tenant
- kubernetes
- aa
- JEUS6
- 쿠버네티스
- OpenStack
- k8s
- git
- Architecture
- aws
- 아키텍처
- openstack token issue
- JEUS7
- 마이크로서비스 아키텍처
- Docker
- MSA
- jeus
- API Gateway
- 오픈스택
- node.js
- JBoss
- SA
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |