
티스토리 뷰
개요
앞선 포스팅에서 마이크로서비스 분산DB 환경에서 고려되어야 할 사항에 대해 살펴보았다. 자세한 내용은 아래 포스팅을 참고하기 바란다.
- 마이크로서비스 데이터베이스 분리 설계 : https://waspro.tistory.com/729
- 마이크로서비스 분산DB 설계 (분산DB 데이터 분할, 동기화 설계) : https://waspro.tistory.com/726
- 마이크로서비스 분산DB 설계 (분산DB 조회 설계) : https://waspro.tistory.com/724
- 마이크로서비스 아키텍처의 기준과 DB 분리 : https://waspro.tistory.com/718
이번 포스팅에서는 데이터베이스 Schema 분리에 대해 알아보도록 하자. 지금까지 데이터베이스 분리 또는 스키마 분리에 대한 다양한 패턴에 대해 알아보았지만, 이를 성공적으로 달성하기 위해서는 데이터베이스 분해와 관련된 몇가지 문제를 해소해야 한다. 이번 포스팅에서는 데이터 분해 패턴을 살펴보고 이러한 패턴이 미칠 수 있는 영향에 대해 알아보도록 하자.
분할 패턴 1. 테이블 분리
둘 이상의 서비스 경계에 걸쳐 분할해야 하는 모놀리스 단일 테이블이 존재할 수 있다. 아래와 같이 기존 통합DB의 특정 테이블은 CUSTID, PW, CName, TransID, Credit 정보를 모두 포함하고 있었으며, 이를 고객서비스와 이체서비스에 각각 필요로 하는 Column 기준으로 테이블을 분할할 필요가 있다.
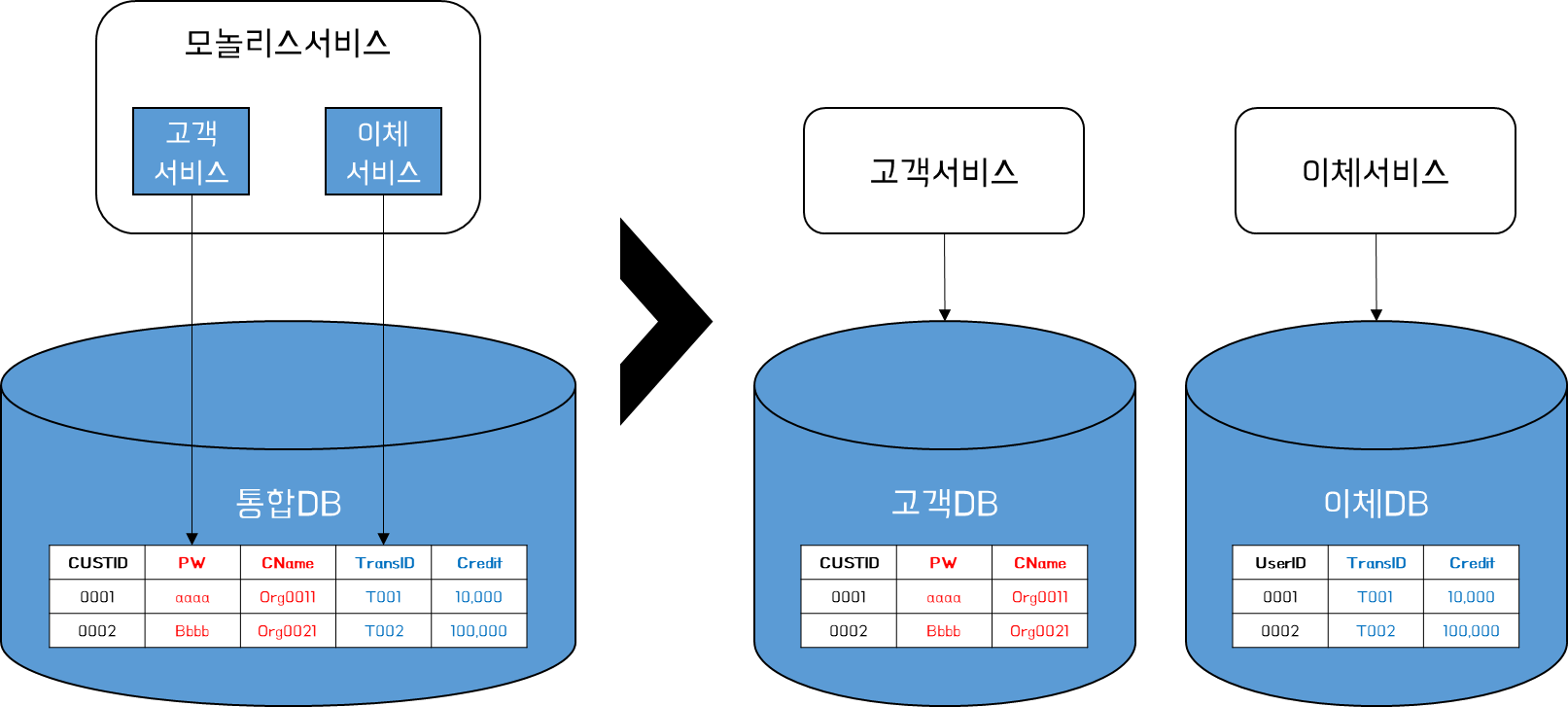
이 패턴은 Column 별로 데이터 소유권을 쉽게 분리할 수 있을 것처럼 보인다. 그러나 실제로는 여러 마이크로서비스에서 동일한 Column을 업데이트하는 경우가 발생할 수 있다.
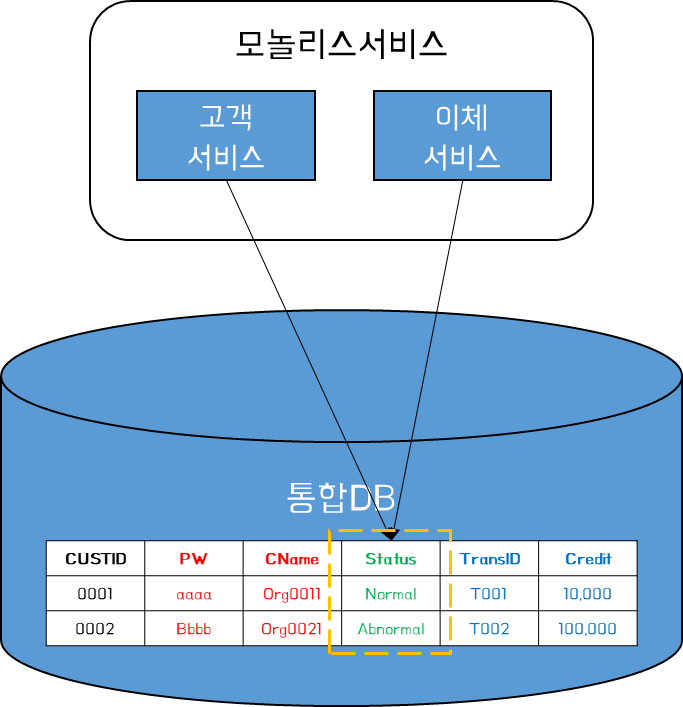
예를 들어 위와 같이 Status라는 컬럼의 경우 고객서비스와 이체서비스 양쪽에서 모두 업데이트를 관리하는 열이라고 가정 해보자. 고객서비스의 경우 특정 기관을 통해 필수로 확인해야 하는 고객정보(주민번호, 이름, 성별 등)가 변경되었는지 확인하여 업데이트 하며, 이체 서비스의 경우 Status 컬럼 중 Normal인 Row에 대해 계좌번호 유효성 검사 후 정상일 경우 Success로 변경하여 업데이트 한다고 가정하자. 이 경우 고객의 상태는 고객서비스에서 관리되어야 하며, 계좌 관리의 경우 이체서비스에서 관리되어야 한다.
물론 공유 컬럼에 대해 대표 서비스를 지정하고, 대표 서비스의 API를 호출하여 CUD를 요청할 수 있다. 다만, 이와 같은 테이블 분할의 근본적인 문제는 데이터베이스 트랜잭션이 제공하는 안전성을 상실한다는 점이다. 이후 포스팅에서 계속 다루겠지만, 분산DB 환경에서의 트랜잭션 문제와 이를 보장하기 위한 SAGA 패턴에 대해서 이해하고 분산트랜잭션 환경을 설계해야 할 것이다.
분할 패턴 2. Foreign-Key Relationship 활용
아래 모놀리스 서비스 내 고객 서비스는 고객 정보를 저장하고, 이체 서비스는 입금, 출금 관련 정보를 저장한다.
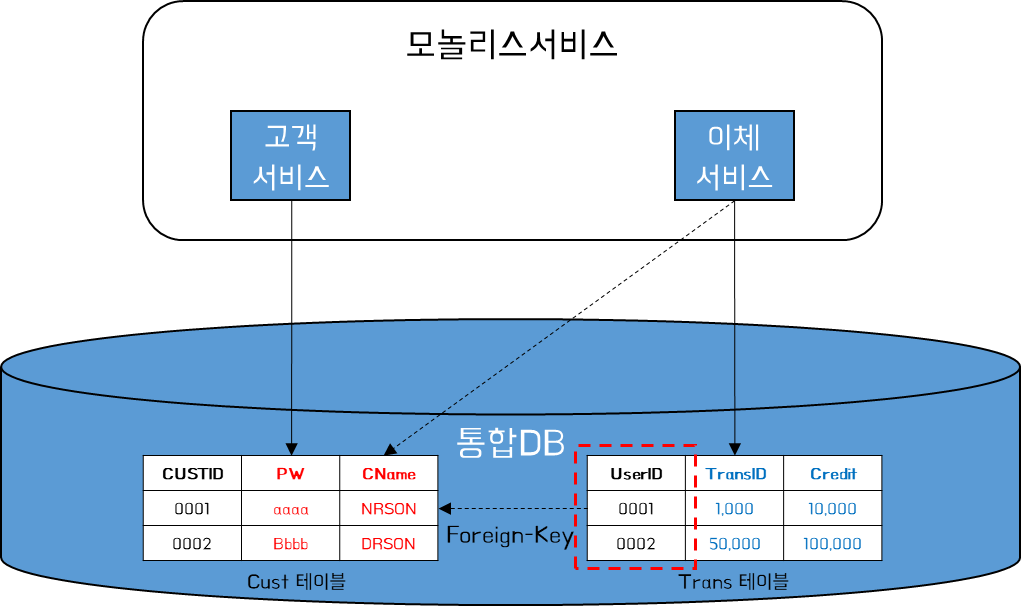
매달 말에는 각 사용자 별 입/출금 내역을 정리하여 고객 이메일로 전송하는 배치업무가 있다고 가정해 보자. Trans 테이블은 UserID별로 매달 기간을 기준으로 TrandID와 Credit을 조합하여 리포트를 작성한다. 그리고 '0001님은 21년 11월 한달 동안 10,000원을 입금하고, 1,000원을 이체하여 총 +9,000원 계좌 내 금액이 증가하였습니다.'는 말보다는 'NRSON님은 21년 11월 한달 동안 10,000원을 입금하고, 1,000원을 이체하여 총 +9,000원 계좌 내 금액이 증가하였습니다.'라고 표현하고 싶을 것이다. 이를 위해, Trans 테이블에서 Cust 테이블로 정보를 결합해야 한다.
Schema에서 Foreign-Key RelationShip을 정의하여, Trans 테이블의 행이 Cust 테이블의 행과 관계가 있는 것으로 식별한다. 이러한 관계를 정의함으로써 기본 데이터베이스 엔진은 데이터 일관성을 보장할 수 있다. 즉, Trans 테이블의 행이 Cust 테이블의 행을 참조하는 경우 행이 존재함을 알 수 있다. 즉 Trans 테이블에서 언제든지 Cust 테이블의 CName(Customer Name)을 얻어올 수 있다는 의미이다. 또한 이러한 외래 키 관계를 통해 데이터베이스 엔진은 조인 작업이 최대한 빨리 수행되도록 성능 최적화를 수행할 수 있다.
물론 이와 같은 패턴은 단일 DB 내의 여러 테이블 간 관계를 정의할 수 있을 경우에만 사용이 가능하다. 따라서 고객서비스와 이체서비스가 독립적인 서비스로 분리되는 시점 특히 분산DB로 구성되는 경우에는 Foreign-Key를 적용할 수 없게 되므로, 다음과 같은 고민을 해야 할 것이다. 먼저, 다른 마이크로서비스의 데이터를 조회하는 방법은 무엇이 있을까? 그리고 데이터 정합성은 어떻게 보장할 것인가?
데이터 조회 방안 (어플리케이션 조인)
월말 정보를 생성할 때 이체 서비스는 먼저 이체 테이블을 쿼리하여 지난 달의 입금, 출금 목록을 추출한다. 이 시점에서 CUSTID와 CName이 필요하다.
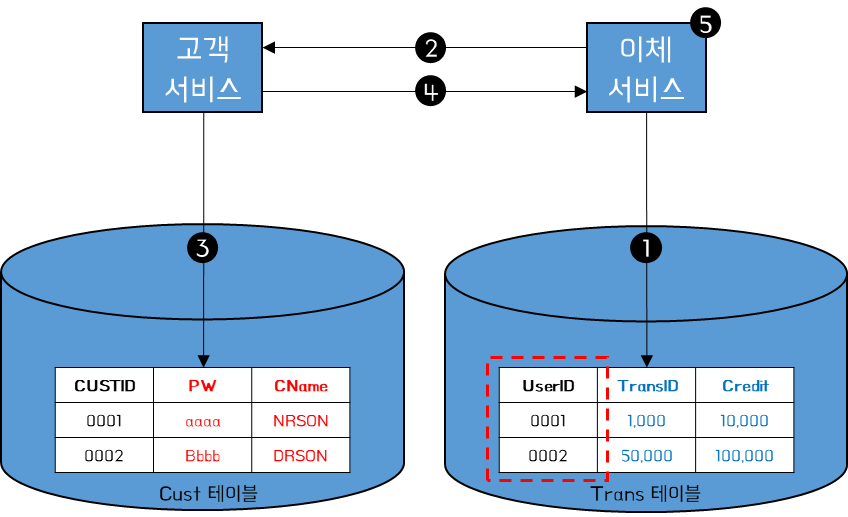
위와 같은 경우 다음과 같은 순서로 서비스가 처리된다.
- 1. UserID별로 월 단위 입금, 출금 내역 조회
- 2. UserID에 대한 세부 정보 요청
- 3. 세부 정보 Cust 테이블 내 조회
- 4. 조회 결과 리턴
- 5. API Composition
논리적으로 조인 작업은 여전히 발생하고 있지만 이제는 데이터베이스가 아니라 이체 서비스(어플리케이션) 내에서 발생한다. JOIN을 서비스 내에서 처리하는 것은 굉장히 비효율적인 방식이라고 볼 수 있다. 데이터베이스가 Join 처리에 특화된 엔지임을 감안해야 하며, 어플리케이션은 이 Join 처리를 위해 비효율적인 루프를 반복적으로 수행해야 할 것이다.
이 상황에서 해당 트랜잭션의 전체 대기 시간이 급격하게 증가할 것이고, 특히나 대량/대용량 쿼리 결과에 따른 Join 처리에서는 더더욱 그 차이가 급격하게 발생할 것임이 자명하다. 앞서 서두에 밝힌바와 같이 매월 사용자별 입/출금 내역을 이메일로 발신하는 작업은 실시간 성의 처리가 아니므로 크게 문제가 되지 않을 수 있다. 매월 리포트가 9시에 오던 10시에 오던 사실 크게 중요하지 않기 때문이다. 그러나 이것이 빈번한 작업이라면 더 큰 문제가 될 수 있다. 고객 서비스에서 CUSTID를 대량으로 조회할 경우 로컬로 캐싱하여 이러한 지연 시간 증가의 영향을 완화할 수 있다.
또한, MSA 분산DB 조회 패턴으로 많이 사용되는 CQRS 설계를 적용해 볼 수 있다. CQRS는 비동기 Message Queue 등을 이용하여 공유 테이블에 대해 CQRS DB로 복제하고, 이를 독립된 분산DB를 하나의 DB로 모음으로써 View Join 또는 Table Join할 수 있도록 제공하는 형태를 활용할 수 있다.
데이터 정합성 보장
더 까다로운 고려 사항은 고객서비스와 이체서비스가 별도의 서비스이고 별도의 스키마를 사용하면 데이터 불일치가 발생할 수 있다는 점이다. 단일 스키마를 사용하면 이체 테이블에 해당 행에 대한 참조가 있는 경우 고객 테이블의 행을 삭제할 수 없지만, 분리 된 환경에서는 상호간 정합성을 보장하는 것이 무엇보다 까다로운 일이 아닐 수 없다.
삭제 전 확인
고객 테이블에서 레코드를 제거할 때 이체 서비스에 확인하여 레코드에 대한 참조가 없는지 확인하는 방법이다. 다만 이와 같은 방법은 올바르게 동작한다고 보장하기 어렵다는 문제가 있다. 예를 들어 CUSTID 0001을 삭제하고 싶다고 가정해 보자. 고객 서비스에서 이체 서비스쪽으로 현재 CUSTID를 참조하는 행이 있는지를 묻고 현재 없다는 답변을 받아 삭제를 진행하고자 한다. 이때 삭제하는 것은 문제가 되지 않을까? 이 작업을 수행하는 동안 이체 시스템에서 CUSTID 0001에 대한 새 참조가 생성될 수 있다. 이러한 일이 발생하지 않도록 하려면 삭제가 발생할 때까지 레코드 0001에서 생성되는 새 참조를 중지해야 한다. 즉 해당 Row에 대한 lock이 필요할 수 있고 이는 분산 시스템에서 암시하는 모든 문제가 발생할 수 있다.
레코드가 이미 사용 중인지 확인하는 또 다른 문제는 고객 서비스에서 사실상 역방향 종속성을 생성한다는 것이다. 결국 자체 서비스 내 데이터의 변화를 위해 다른 서비스를 확인해야 한다. 이것은 소비자가 많을질수록 훨씬 더 결합도가 높아지고, 확인해야 할 대상이 증가하는 것이다. 결국 이 작업이 올바르게 구현되었는지 확인하기 어렵고 이로 인해 발생하는 높은 수준의 서비스 결합 때문에 이 옵션을 고려하지 않을 것을 권고한다.
삭제 정상 처리
고객 서비스에 CUSTID에 대한 정보가 없을 수 있다는 사실을 이체 서비스에서 처리하도록 하는 것이다. 주어진 CUSTID를 조회할 수 없는 경우 월별 이체 정보에 "탈퇴한 사용자입니다."와 같은 표시가 되도록 하는 것처럼 간단 할 수 있다 .
이 상황에서 고객 서비스는 이전에 존재했던 CUSTID를 요청할 때 알려줄 수 있다. 예를 들어 410 GONE HTTP Response를 응답 코드로 내려주는 것도 좋은 방법이다. 410은 요청된 리소스를 사용할 수 있었지만 더 이상 존재하지 않음을 의미한다. 특히 해당 HTTP Status Code를 활용하여 데이터 불일치 문제를 추적할 때 활용할 수도 있을 것이다.
CUSTIS 항목이 제거될 때 이벤트를 구독하여 이체 서비스에 알릴 수 있다. CUSTID 삭제 이벤트를 선택할 때 현재 삭제된 Customer 정보를 로컬 데이터베이스에 복사할 수 있다. 이 방법은 특히 서비스 경계를 넘어 단계적 삭제와 같은 작업을 수행하기 위해 분산 시스템을 구현하려는 경우 유용할 수 있다.
삭제 불가
시스템에 불일치가 발생하지 않도록 하는 방법은 고객 서비스의 레코드 삭제를 허용하지 않는 것이다. 기존 시스템에서 항목을 삭제하는 것과 유사한 소프트 삭제 기능을 구현할 수 있다. 예를 들어 상태 열을 사용하여 행을 사용할 수 없는 것으로 표시할 수 있다. 이러한 상황에서 CUSTID는 여전히 이체 서비스에서 호출 할 수 있는 상태가 된다.
그럼 삭제는 어떻게 처리해야 할까? 개인적으로, 고객서비스에서 CUSTID 삭제권한을 허용하지 않는 것과 이체 서비스에서 누락된 레코드를 처리할 수 있도록 하는 방법을 적용하여 방어로직을 구현하는 방법 등이 있을 것이다.
결론
foreign-key relationship을 해소하기 위해 고민하는 것은 위와 같이 중요하지만, 그보다 먼저 데이터의 분할에 대해 다시한번 고민해 볼 필요가 있다. 별도의 서비스로 분할할 경우 데이터 무결성 문제를 고려해야 하며, 스키마를 더 크게 가져감으로써 손쉽게 데이터를 관리할 수 있다는 점을 기억해야 할 것이다.
'③ 클라우드 > ⓜ MSA' 카테고리의 다른 글
| 마이크로서비스 분산 트랜잭션 관리 (Saga Pattern) (5) | 2021.11.23 |
|---|---|
| 마이크로서비스 분산 트랜잭션 관리 (2Phase Commit) (1) | 2021.11.23 |
| 마이크로서비스 데이터베이스 분리 설계 (0) | 2021.11.22 |
| 마이크로서비스 분산DB 데이터 분할, 동기화 설계 (0) | 2021.11.21 |
| 마이크로서비스 분산DB 조회 설계 (0) | 2021.11.14 |
- Total
- Today
- Yesterday
- 오픈스택
- SWA
- JEUS7
- apache
- SA
- TA
- jeus
- MSA
- 마이크로서비스
- node.js
- k8s
- aws
- Architecture
- OpenStack
- Docker
- JBoss
- openstack tenant
- API Gateway
- 아키텍처
- git
- aa
- wildfly
- Da
- JEUS6
- 마이크로서비스 아키텍처
- nodejs
- kubernetes
- webtob
- openstack token issue
- 쿠버네티스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |