
티스토리 뷰
개요
앞선 포스팅에서 마이크로서비스 분산DB 환경에서 데이터 조회를 위한 방안에 대해 살펴보았다. 자세한 내용은 아래 포스팅을 참고하기 바란다.
- 마이크로서비스 분산DB 설계 (분산DB 조회 설계) : https://waspro.tistory.com/724
- 마이크로서비스 아키텍처의 기준과 DB 분리 : https://waspro.tistory.com/718
앞서 살펴본 분산 DB 조회 설계에서는 이미 분할된 데이터에 대한 접근을 어떻게 효과적으로 할 것이냐에 포커싱을 맞추었다면, 이번 포스팅에서는 어떻게 데이터를 모놀리식 DB에서 분할할 것인냐에 대해 알아보도록 하자.
중요한 포인트는 바로 특정 데이터가 어느 분산 DB에 존재하는 것이 좋은지에 대한 결정을 내리는 일이다. 모놀리스에서 서비스를 분리할 때 일부 데이터는 함께 제공되어야 하고 일부는 그대로 있어야 한다. 또한 일부는 타 마이크로서비스로 이전될 수도 있다.
분산 데이터 분할(데이터 소유권) 설계
앞서 조회 설계 패턴에서도 이야기 했듯 데이터베이스를 설계하는 핵심 포인트는 바로 서비스간 호출 빈도를 줄일 수 있는 데이터 모델링이라고 할 수 있다. 각 서비스가 독립적으로 이용하는 데이터는 해당 서비스 전용 분산 DB로 마이그레이션하고, 공통으로 사용하는 DB는 공통 DB 또는 이와 상응하는 저장소에 저장하고 공유한다.
아래와 같은 경우 고객데이터를 모놀리스에서 고객DB로 으로 이동한다. 이때, 고객DB에 저장된 고객관련 테이블에 접근하고자 할 경우 모놀리스 어플리케이션은 물론 타 마이크로서비스는 고객 서비스의 API를 호출하여 데이터를 읽거나 변경 사항을 반영하도록 해야 한다.
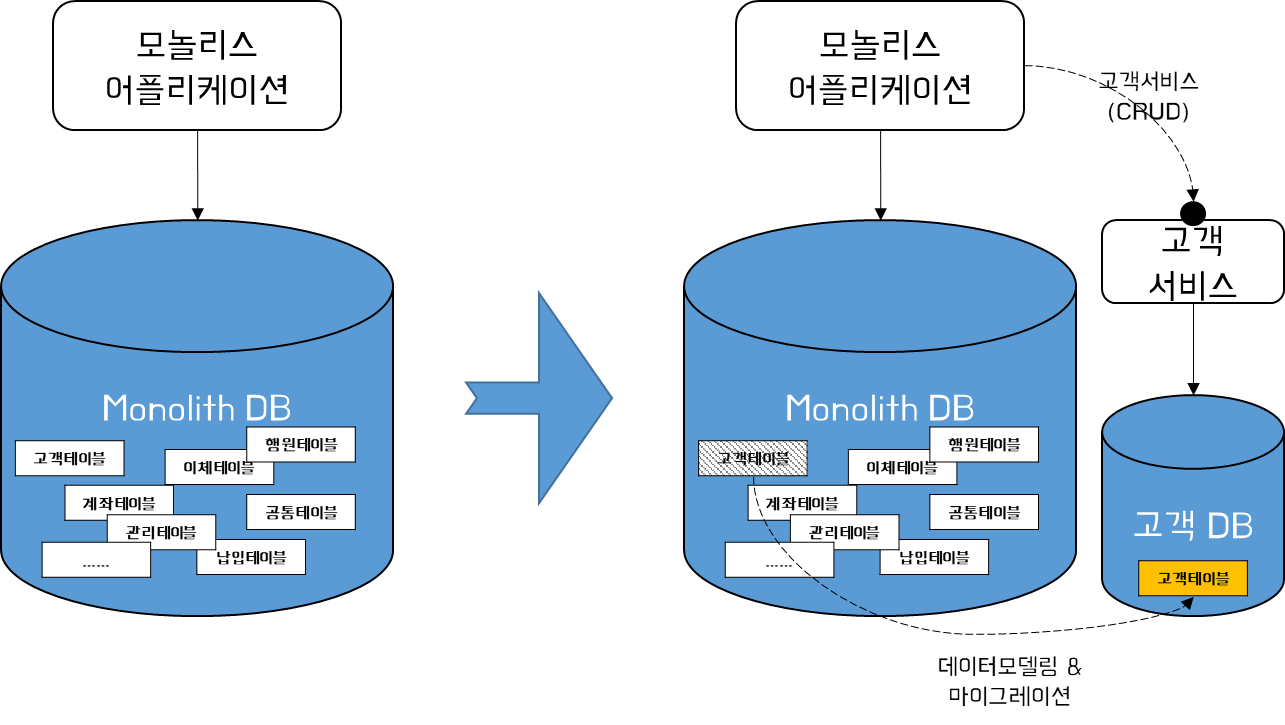
굉장히 간단한 것처럼 설명했지만, 사실 고객테이블을 모놀리식 DB에서 분리해 내는 것에는 복잡한 문제들이 있다. 먼저 Foreign-key constraints, 분산트랜잭션 환경에 따른 데이터 정합성 관리 문제, 보상처리 설계 등 굵직굵직한 이슈들을 해소해야 테이블을 분할할 수 있다. 이에 대해서는 5, 6, 7회차 포스팅에서 상세히 다뤄볼 예정이니 이를 참하고 하기 바라며, 설계 요점만 짚어 보고 넘어가도록 하자.
데이터 동기화
다음으로 데이터베이스가 분할 되었을 경우 데이터 동기화가 필요한 상황들이 발생하게 된다. 예를 들어 병행운영(as-is app과 to-be app간의 운영기간 중첩)을 해야 한다던지, 배치를 위한 조회용도로 데이터를 복제해야 한다던지, Join을 위한 분산DB간 조회를 해야 한다던지 등 다양한 케이스에서 데이터 동기화 요건은 발생할 수 있다.
애플리케이션 레벨 데이터 동기화
먼저 살펴볼 동기화 패턴은 애플리케이션 레벨에서의 데이터 동기화이다. 애플리케이션 레벨에서 두 데이터소스 간의 동기화를 수행 직접 수행하는 방식이다. 데이터베이스의 마이그레이션 요건은 여러 형태로 존재한다. DBMS가 갖고 있는 특징을 적용하기 위함이라던지, MSA 환경에 분산DB를 적용하기 위해 오픈DB로의 전환을 목적으로 한다던지, 라이선스 비용을 줄이기 위함이라던지, OGG와 같은 DR 구성 요건으로 인해 전환한다던지, 그 목적에 따라 DB를 구성하고, 데이터를 전환하는 과정이 발생하게 된다.
데이터 대량 동기화
데이터 동기화를 위해 제일 먼저 수행해야 하는 것은 Source 데이터베이스에서 Target 데이터베이스로의 데이터 일괄 복제하는 것이다. 복제가 진행되는 동안 기존 시스템에 반영된 데이터로 인해 복제 완료된 Target 데이터베이스와 데이터 정합성 문제가 발생할 수 있다. 복제가 완료되면 이후 변경사항에 대해 CDC 도구를 통해 동기화할 수 있으며, 동기화가 완료되는 시점에 Target 데이터베이스를 어플리케이션 서비스에 배포할 수 있다.
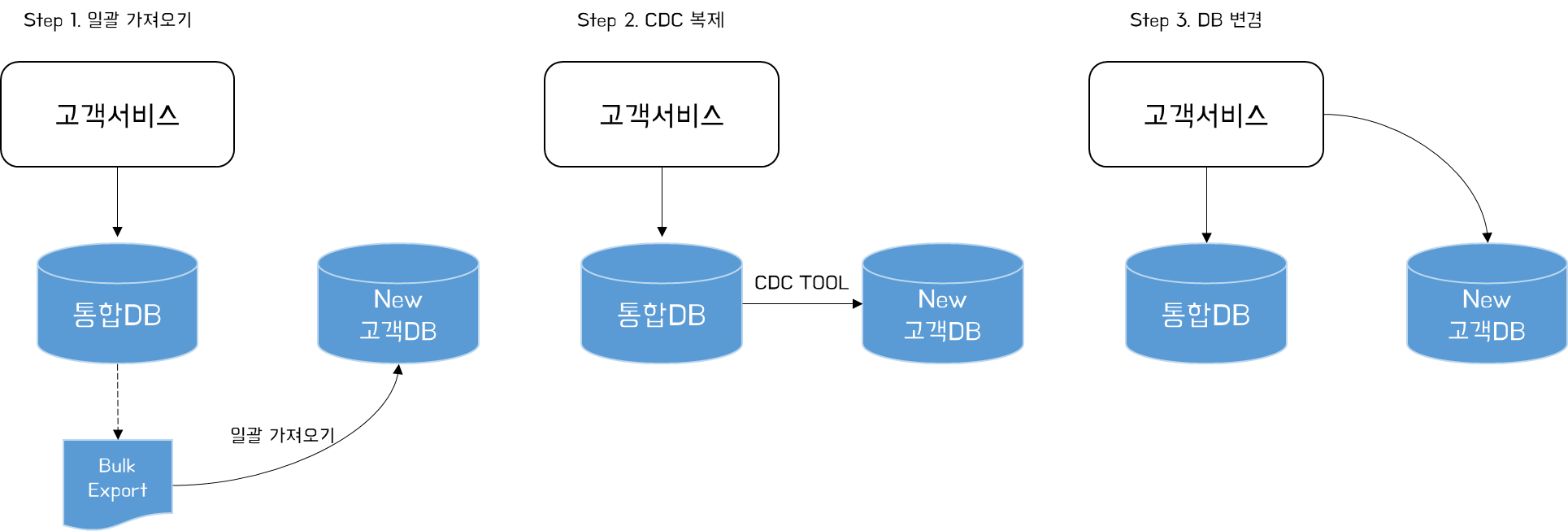
두 데이터베이스가 동기화되어 모든 데이터를 기록하는 새 버전의 애플리케이션이 배포되었다. 이후에도 두 데이터베이스를 함께 사용하고자 할 경우 동기화는 지속적으로 이루어져야 한다. 여러 형태의 동기화 패턴에 대해 알아보자.
양방향 쓰기
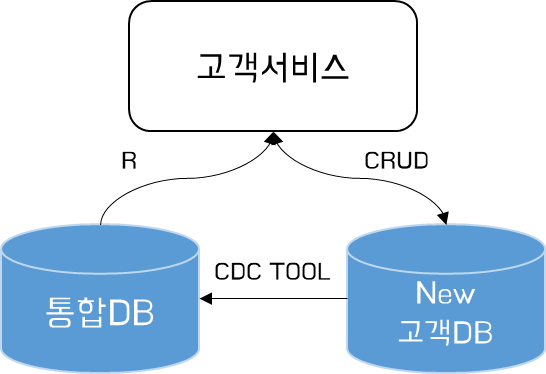
먼저 양방향 쓰기이다. 양방향 쓰기는 통합DB, New 고객DB 양쪽에 동일한 CUD를 발생시키는 방식이다.

양쪽에 동일한 CUD가 발생되기 때문에 정합성 유지가 간편하지만, 네트워크 비용이 두배로 발생한다는 단점이 있다. 또한, DB별 성능차로 인한 타이밍 이슈를 해소하기 위해 R(Read)의 경우 양쪽 DB 중 한쪽을 선택하는 것이 좋다. 나머지 DB는 장애 시 FailOver 용도로 활용할 수 있도록 Read 권한을 제어한다.
단일 DB 쓰기
단방향 쓰기는 양쪽 DB간 데이터 동기화를 위한 별도의 수단이 필요하다는 점이 추가되지만, 일반적으로 가장 선호하는 방식이다. 단방향 쓰기를 통해 트랜잭션 실패에 유연하게 대응할 수 있으며, Read를 확장하므로써 높은 성능을 뽑아낼 수 있다.
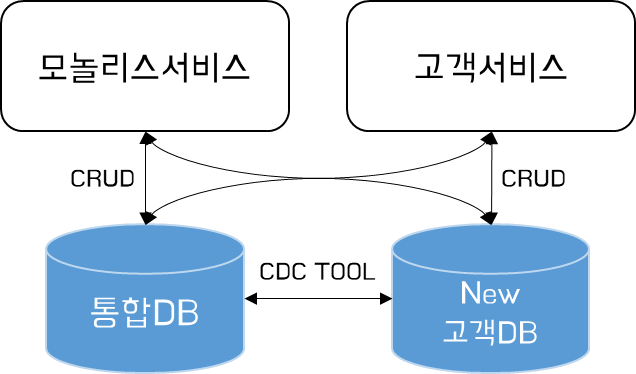
FullMesh 방식
Read/Write를 모놀리스와 마이크로서비스가 모두 데이터에 액세스하는 방식이다. 이 패턴이 작동하려면 모놀리스와 마이크로서비스 모두 데이터베이스 전체에서 적절한 동기화를 보장해야 한다. 둘 중 하나가 잘못되면 문제가 발생할 수 있다.
결론
이번 포스팅에서는 데이터 분할 설계 및 데이터 동기화 패턴에 대해 알아 보았다.
데이터 분할 설계의 경우 테이블을 쪼개기 위한 선행되어야 하는 많은 작업들이 존재한다. 이에 대해서는 차차 알아보기로 하고, 분할된 데이터에 접근하기 위해 모놀리스 서비스는 직접 데이터에 접근하는 것이 아닌 API를 통해 접근하는 것이 보다 결합도를 낮추는 설계 패턴이라 할 수 있다.
데이터 동기화의 경우 데이터 마이그레이션 과정을 포함한 분할 된 데이터 간 상호 유지하는 방법에 대해 알아 보았다. 가능한 데이터 정합성을 위해 Read는 하나의 DB에서 접근하도록 구성하는 것이 효과적이며, CDC 도구를 적극 활용하는 것을 권장한다.
사실 이번 포스팅의 목적은 설계에 있지는 않다. 설계에 목적이 있었다면, 보다 다양한 패턴을 다뤄보고 하겠지만, 이 포스팅이 원하는 바는 바로 분산 트랜잭션과 분산 DB 환경에 대한 마이크로서비스 아키텍처의 대응 방안을 마련해 보자는 취지이다. 이로 인해 앞 3~4개의 포스팅은 개념적인 부분들만 짚어 보고 넘어가는 경향이 있을 수 있으나, 뒷부분에서 논의할 핵심 패턴의 기반이 되는 정보라는 점 이야기 하고 이번 포스팅을 마무리하고자 한다.
'③ 클라우드 > ⓜ MSA' 카테고리의 다른 글
| 마이크로서비스 Schema 분리 설계 (테이블 분리, 외래키 참조관계, 조인, 데이터 정합성 보장) (0) | 2021.11.22 |
|---|---|
| 마이크로서비스 데이터베이스 분리 설계 (0) | 2021.11.22 |
| 마이크로서비스 분산DB 조회 설계 (0) | 2021.11.14 |
| 마이크로서비스 아키텍처의 기준과 DB 분리 (7) | 2021.09.11 |
| 성공적인 DevSecOps 구현하기 (0) | 2021.03.19 |
- Total
- Today
- Yesterday
- 오픈스택
- API Gateway
- kubernetes
- openstack tenant
- JEUS7
- 쿠버네티스
- apache
- JEUS6
- 아키텍처
- nodejs
- Docker
- SA
- JBoss
- jeus
- TA
- wildfly
- git
- aa
- OpenStack
- Architecture
- aws
- k8s
- SWA
- webtob
- Da
- 마이크로서비스
- 마이크로서비스 아키텍처
- node.js
- MSA
- openstack token issue
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |