
티스토리 뷰
서론
지난 시간에 살펴본 Amazon CloudWatch가 모니터링 중심의 서비스라면, Amazon ElasticSearch는 로깅 중심의 Telemetry 서비스이다. Amazon CloudWatch에 대해 알아보고자 할 경우 다음을 참고한다.
[② 클라우드 마스터/ⓐ AWS] - AWS 리소스 및 애플리케이션 모니터링 서비스 (CloudWatch)
이번 포스팅에서는 Amazon CloudWatch를 활용하여 EKS Cluster의 로그를 수집하고 표출하는 과정에 대해 알아보도록 하자. ELK에 대해 알아보고자 할 경우 다음을 참고한다.
EFK를 활용하면, AWS의 다양한 Managed Service를 통합하여 로그를 수집하고 표출함으로써 로그가 필요한 다양한 시점에 활용 가능하도록 제공한다.
AWS는 몇가지 로그 수집 방안을 제공하지만, 본 가이드에서는 아래와 같은 아키텍처로 로그를 수집하고 표출하도록 구성할 예정이다.
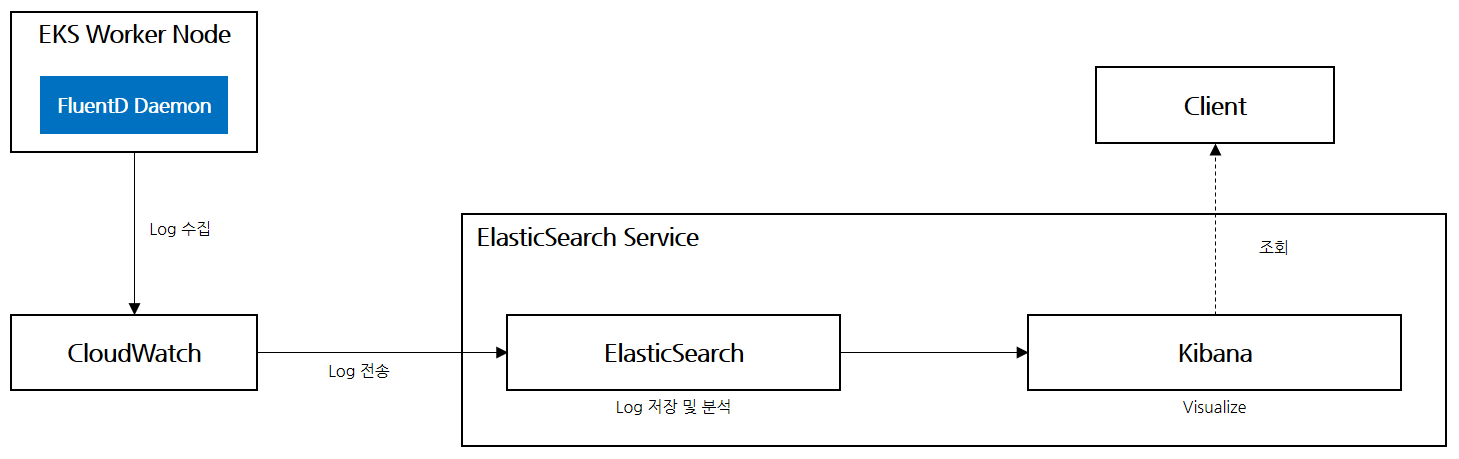
- FluentD : EKS Worker Node에 DaemonSet으로 배포되어 개별 로그를 수집하는 역할
- CloudWatch : 수집된 로그를 ElasticSearch 로그저장소로 전송
- ElasticSearch : Log 저장소 및 분석하는 핵심 엔진
- Kibana : 분석된 결과를 Visualize하는 대시보드
Amazon ElasticSearch Service 구성
1) Policy & Role 구성
2) FluentD 구성
3) ElasticSearch 구성
4) CloudWatch 구성
5) Kibana 모니터링
Policy & Role 구성
앞서 EKS와 CloudWatch 연동 구성을 따라 했다면, 아래 내용을 스킵해도 된다. 연동 구성 정보는 다음을 참고할 수 있다.
[② 클라우드 마스터/ⓐ AWS] - AWS 리소스 및 애플리케이션 모니터링 서비스 (CloudWatch)
연동이 구성되면 아래와 같이 Worker Node를 기동하는 Role에 CloudWatchAgentServerPolicy가 추가되어야 한다.

Role이 구성되면, 각각 CloudWatch를 구성하기 위한 Namespace, ServiceAccount, ConfigMap, DaemonSet 등이 구성되어야 한다. 자세한 사항은 위 포스팅 글을 참고하기 바란다.
FluentD 구성
1) ConfigMap 구성
cluster-info라는 configmap을 생성한다. 해당 configmap을 사용할 경우 cluster과 region을 업데이트한다.
[root@ip-192-168-114-198 yaml]# kubectl create configmap cluster-info --from-literal=cluster.name=NRSON-EKS-CLUSTER --from-literal=logs.region=ap-northeast-2 -n amazon-cloudwatch
configmap/cluster-info created
[root@ip-192-168-114-198 yaml]#2) Multiline Log Support
FluentD는 멀티라인으로 구성된 로그를 표출하기 위해 다음과 같은 시작줄 감지 기능과 라인의 범위를 지정할 수 있다. 멀티라인을 판단하기 위해 공백이 없는 문자로 시작하는 경우 새로운 멀티라인으로 인식한다. 이와 같은 기본 규칙에서 제외하여 로그를 관리하고자 할 경우 다음과 같은 변경이 필요하다.
FluentD는 다음에서 Template yaml 파일을 다운로드 받을 수 있다.
[root@ip-192-168-114-198 yaml]# curl -O https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/fluentd/fluentd.yaml
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11041 100 11041 0 0 24923 0 --:--:-- --:--:-- --:--:-- 24923
[root@ip-192-168-114-198 yaml]#다운로드 받은 fluentd.yaml 파일을 다음과 같이 수정한다.
<source>
@type tail
@id in_tail_container_logs
@label @containers
path /var/log/containers/*.log
exclude_path ["full_pathname_of_log_file*", "full_pathname_of_log_file2*"]위와 같이 exclude_path에 로그파일을 지정하여 제외할 수 있다.
3) 로그 볼륨 관리
FluentD는 EKS는 물론 FluentD 자체에서 생성하는 로그까지 모두 수집하여 전송한다. 이는 때로 필요할수는 있으나, 오히려 많은 로그양으로 인해 네트워크와 I/O를 소모하여 성능 저하를 초래한다. 따라서 로그 수집 대상에서 제외하는 아래와 같은 구성을 권고한다.
- 삭제
...
...
<source>
@type tail
@id in_tail_container_logs
@label @containers
path /var/log/containers/*.log
exclude_path ["/var/log/containers/cloudwatch-agent*", "/var/log/containers/fluentd*"]
pos_file /var/log/fluentd-containers.log.pos
tag *
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
...
...
<label @fluentdlogs>
<filter **>
@type kubernetes_metadata
@id filter_kube_metadata_fluentd
</filter>
<filter **>
@type record_transformer
@id filter_fluentd_stream_transformer
<record>
stream_name ${tag_parts[3]}
</record>
</filter>
<match **>
@type relabel
@label @NORMAL
</match>
</label>
...
...위를 제거함으로써 fluentd-containers 애플리케이션 로그와 kuberentes_metadata를 수집 대상에서 제외한다.
- 추가
...
...
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_containers_stream_transformer
<record>
stream_name ${tag_parts[3]}
</record>
</filter>
...
...
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_cwagent_stream_transformer
<record>
stream_name ${tag_parts[3]}
</record>
</filter>
...
...
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_systemd_stream_transformer
<record>
stream_name ${tag}-${record["hostname"]}
</record>
</filter>
...
...
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_containers_stream_transformer_host
<record>
stream_name ${tag}-${record["host"]}
</record>
</filter>
...
...@type이 record_transformer인 4개의 filter에 다음과 같이 remove_keys를 추가한다.
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id는 CloudWatch로 전송되는 로그에 Kubernetes 메타 데이터가 추가되는 것을 제거하여 로그의 사이즈를 줄이고자 함에 있다.
4) DaemonSet 반영
수정된 fluentd.yaml을 반영한다.
[root@ip-192-168-114-198 efk]# kubectl apply -f fluentd.yaml
serviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd-role created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-role-binding created
configmap/fluentd-config created
daemonset.apps/fluentd-cloudwatch created
[root@ip-192-168-114-198 efk]#본 포스팅에서 적용한 yaml 파일은 다음과 같다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: amazon-cloudwatch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd-role
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- pods/logs
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluentd-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluentd-role
subjects:
- kind: ServiceAccount
name: fluentd
namespace: amazon-cloudwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: amazon-cloudwatch
labels:
k8s-app: fluentd-cloudwatch
data:
fluent.conf: |
@include containers.conf
@include systemd.conf
@include host.conf
<match fluent.**>
@type null
</match>
containers.conf: |
<source>
@type tail
@id in_tail_container_logs
@label @containers
path /var/log/containers/*.log
exclude_path ["/var/log/containers/cloudwatch-agent*", "/var/log/containers/fluentd*"]
pos_file /var/log/fluentd-containers.log.pos
tag *
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<source>
@type tail
@id in_tail_cwagent_logs
@label @cwagentlogs
path /var/log/containers/cloudwatch-agent*
pos_file /var/log/cloudwatch-agent.log.pos
tag *
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<label @containers>
<filter **>
@type kubernetes_metadata
@id filter_kube_metadata
</filter>
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_containers_stream_transformer
<record>
stream_name ${tag_parts[3]}
</record>
</filter>
<filter **>
@type concat
key log
multiline_start_regexp /^\S/
separator ""
flush_interval 5
timeout_label @NORMAL
</filter>
<match **>
@type relabel
@label @NORMAL
</match>
</label>
<label @cwagentlogs>
<filter **>
@type kubernetes_metadata
@id filter_kube_metadata_cwagent
</filter>
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_cwagent_stream_transformer
<record>
stream_name ${tag_parts[3]}
</record>
</filter>
<filter **>
@type concat
key log
multiline_start_regexp /^\d{4}[-/]\d{1,2}[-/]\d{1,2}/
separator ""
flush_interval 5
timeout_label @NORMAL
</filter>
<match **>
@type relabel
@label @NORMAL
</match>
</label>
<label @NORMAL>
<match **>
@type cloudwatch_logs
@id out_cloudwatch_logs_containers
region "#{ENV.fetch('REGION')}"
log_group_name "/aws/containerinsights/#{ENV.fetch('CLUSTER_NAME')}/application"
log_stream_name_key stream_name
remove_log_stream_name_key true
auto_create_stream true
<buffer>
flush_interval 5
chunk_limit_size 2m
queued_chunks_limit_size 32
retry_forever true
</buffer>
</match>
</label>
systemd.conf: |
<source>
@type systemd
@id in_systemd_kubelet
@label @systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<entry>
field_map {"MESSAGE": "message", "_HOSTNAME": "hostname", "_SYSTEMD_UNIT": "systemd_unit"}
field_map_strict true
</entry>
path /var/log/journal
<storage>
@type local
persistent true
path /var/log/fluentd-journald-kubelet-pos.json
</storage>
read_from_head true
tag kubelet.service
</source>
<source>
@type systemd
@id in_systemd_kubeproxy
@label @systemd
filters [{ "_SYSTEMD_UNIT": "kubeproxy.service" }]
<entry>
field_map {"MESSAGE": "message", "_HOSTNAME": "hostname", "_SYSTEMD_UNIT": "systemd_unit"}
field_map_strict true
</entry>
path /var/log/journal
<storage>
@type local
persistent true
path /var/log/fluentd-journald-kubeproxy-pos.json
</storage>
read_from_head true
tag kubeproxy.service
</source>
<source>
@type systemd
@id in_systemd_docker
@label @systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<entry>
field_map {"MESSAGE": "message", "_HOSTNAME": "hostname", "_SYSTEMD_UNIT": "systemd_unit"}
field_map_strict true
</entry>
path /var/log/journal
<storage>
@type local
persistent true
path /var/log/fluentd-journald-docker-pos.json
</storage>
read_from_head true
tag docker.service
</source>
<label @systemd>
<filter **>
@type kubernetes_metadata
@id filter_kube_metadata_systemd
</filter>
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_systemd_stream_transformer
<record>
stream_name ${tag}-${record["hostname"]}
</record>
</filter>
<match **>
@type cloudwatch_logs
@id out_cloudwatch_logs_systemd
region "#{ENV.fetch('REGION')}"
log_group_name "/aws/containerinsights/#{ENV.fetch('CLUSTER_NAME')}/dataplane"
log_stream_name_key stream_name
auto_create_stream true
remove_log_stream_name_key true
<buffer>
flush_interval 5
chunk_limit_size 2m
queued_chunks_limit_size 32
retry_forever true
</buffer>
</match>
</label>
host.conf: |
<source>
@type tail
@id in_tail_dmesg
@label @hostlogs
path /var/log/dmesg
pos_file /var/log/dmesg.log.pos
tag host.dmesg
read_from_head true
<parse>
@type syslog
</parse>
</source>
<source>
@type tail
@id in_tail_secure
@label @hostlogs
path /var/log/secure
pos_file /var/log/secure.log.pos
tag host.secure
read_from_head true
<parse>
@type syslog
</parse>
</source>
<source>
@type tail
@id in_tail_messages
@label @hostlogs
path /var/log/messages
pos_file /var/log/messages.log.pos
tag host.messages
read_from_head true
<parse>
@type syslog
</parse>
</source>
<label @hostlogs>
<filter **>
@type kubernetes_metadata
@id filter_kube_metadata_host
</filter>
<filter **>
@type record_transformer
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_id
@id filter_containers_stream_transformer_host
<record>
stream_name ${tag}-${record["host"]}
</record>
</filter>
<match host.**>
@type cloudwatch_logs
@id out_cloudwatch_logs_host_logs
region "#{ENV.fetch('REGION')}"
log_group_name "/aws/containerinsights/#{ENV.fetch('CLUSTER_NAME')}/host"
log_stream_name_key stream_name
remove_log_stream_name_key true
auto_create_stream true
<buffer>
flush_interval 5
chunk_limit_size 2m
queued_chunks_limit_size 32
retry_forever true
</buffer>
</match>
</label>
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-cloudwatch
namespace: amazon-cloudwatch
spec:
selector:
matchLabels:
k8s-app: fluentd-cloudwatch
template:
metadata:
labels:
k8s-app: fluentd-cloudwatch
annotations:
configHash: 8915de4cf9c3551a8dc74c0137a3e83569d28c71044b0359c2578d2e0461825
spec:
serviceAccountName: fluentd
terminationGracePeriodSeconds: 30
# Because the image's entrypoint requires to write on /fluentd/etc but we mount configmap there which is read-only,
# this initContainers workaround or other is needed.
# See https://github.com/fluent/fluentd-kubernetes-daemonset/issues/90
initContainers:
- name: copy-fluentd-config
image: busybox
command: ['sh', '-c', 'cp /config-volume/..data/* /fluentd/etc']
volumeMounts:
- name: config-volume
mountPath: /config-volume
- name: fluentdconf
mountPath: /fluentd/etc
- name: update-log-driver
image: busybox
command: ['sh','-c','']
containers:
- name: fluentd-cloudwatch
image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-cloudwatch-1.0
env:
- name: REGION
valueFrom:
configMapKeyRef:
name: cluster-info
key: logs.region
- name: CLUSTER_NAME
valueFrom:
configMapKeyRef:
name: cluster-info
key: cluster.name
- name: CI_VERSION
value: "k8s/1.2.3"
resources:
limits:
memory: 400Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: config-volume
mountPath: /config-volume
- name: fluentdconf
mountPath: /fluentd/etc
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: runlogjournal
mountPath: /run/log/journal
readOnly: true
- name: dmesg
mountPath: /var/log/dmesg
readOnly: true
volumes:
- name: config-volume
configMap:
name: fluentd-config
- name: fluentdconf
emptyDir: {}
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: runlogjournal
hostPath:
path: /run/log/journal
- name: dmesg
hostPath:
path: /var/log/dmesg배포가 완료되었으면 아래와 같이 상태를 확인한다.
[root@ip-192-168-114-198 efk]# kubectl get daemonset -n amazon-cloudwatch
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
cloudwatch-agent 2 2 2 2 2 <none> 4h7m
fluentd-cloudwatch 2 2 2 2 2 <none> 117s
[root@ip-192-168-114-198 efk]# CloudWatch DaemonSet과 함께 FluentD DaemonSet이 구성된 것을 확인할 수 있다. 다음으로 CloudWatch에 FluentD를 통해 로그를 수집하고자 하는 로그 그룹이 생성되었는지 확인한다.

위와 같이 NRSON-EKS-CLUSTER에 application, dataplane, host라는 로그 그룹이 생성된 것을 확인할 수 있다.
ElasticSearch 구성
다음으로 ElasticSearch로 이동하여 데이터 저장소 구성 및 Kibana 구성을 진행하도록 한다.
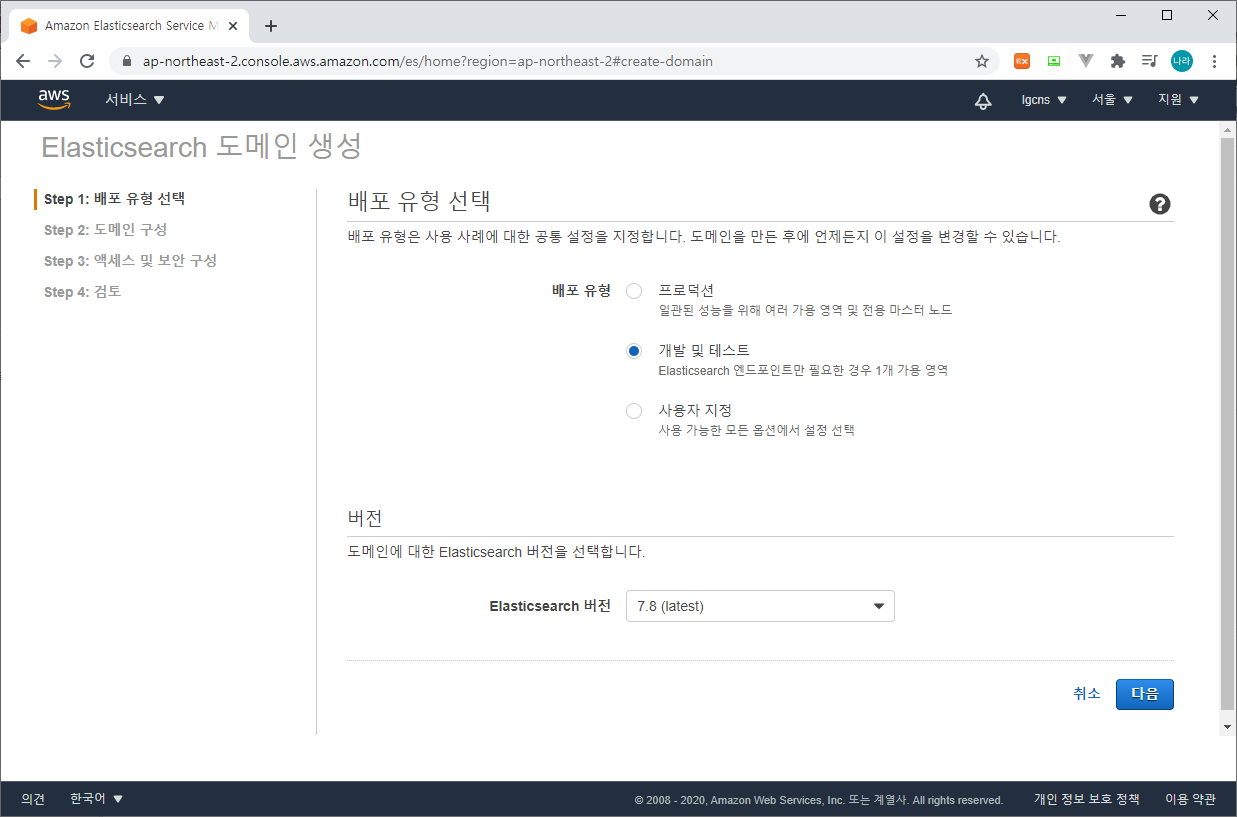
(ElasticSearch Service > 새 도메인 생성)
Step 1 : 배포 유형 선택 (배포 유형은 개발 및 테스트를 선택한다. 운영환경에서는 프로덕션을 선택하여 가용성을 높이도록 한다.)
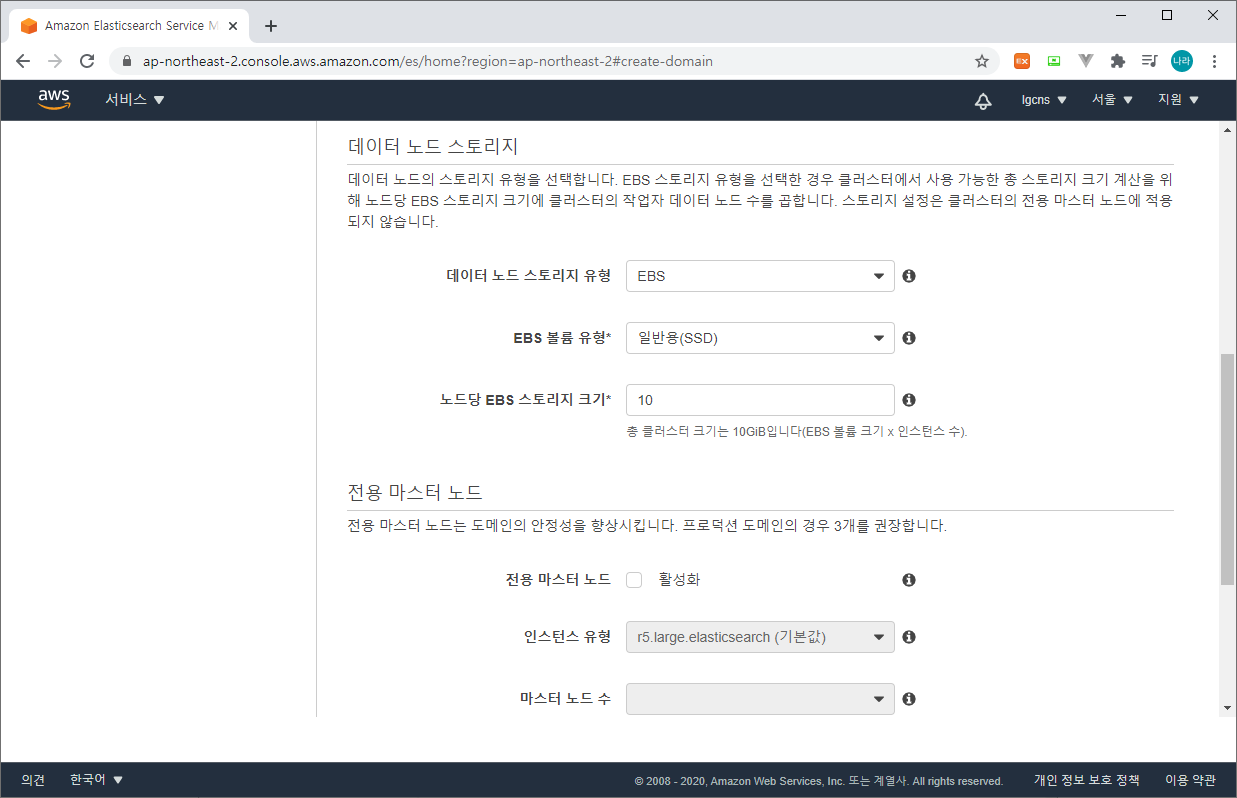
Step 2 : 도메인 구성 (데이터 노드의 인스턴스 유형과 노드 수, 데이터 노드 스토리지를 결정한다. 필요시 전용 마스터 노드를 구성하여 가용성은 높이도록 구성하며, 프로덕션 환경에는 구축을 권고한다.)

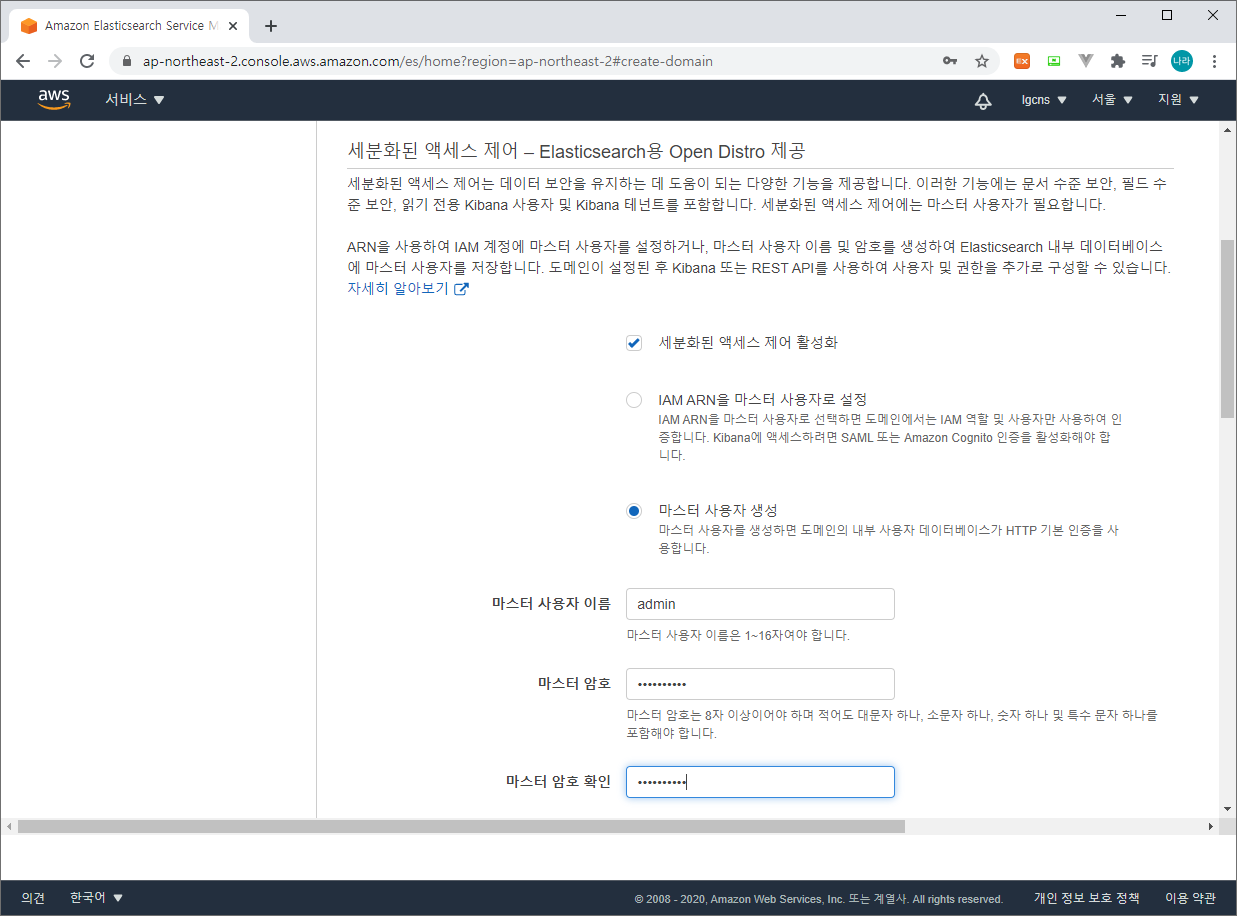
Step 3 : 액세스 및 보안 구성 (네트워크 구성, Kibana Admin 사용자 계정 구성, 엑세스 정책을 등록하고 관리한다.)

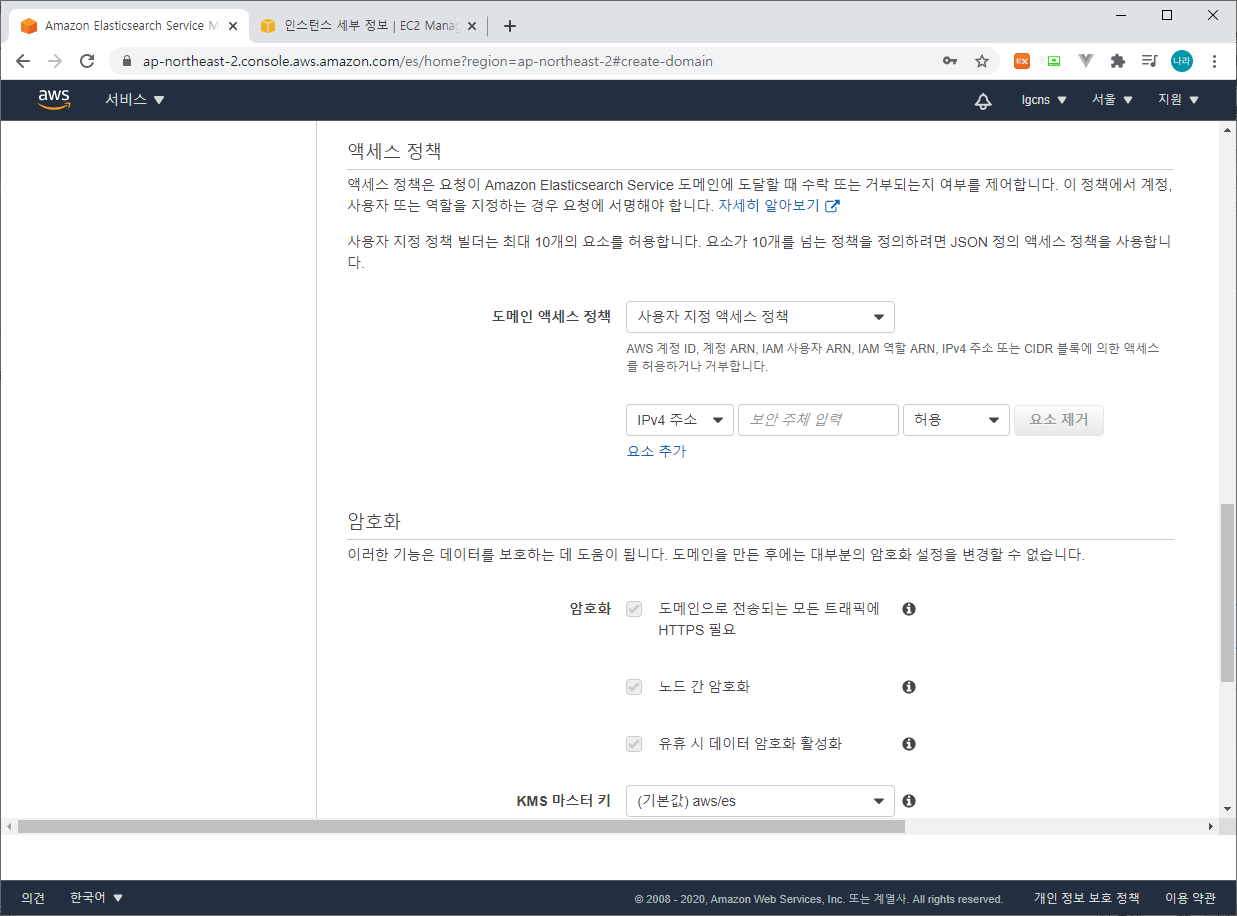
Step 4 : 검토 단계에서 구성 상태를 확인 후 확인을 클릭한다. 대략 ElasticSearch 도메인은 10여분의 생성 시간을 필요로 한다.

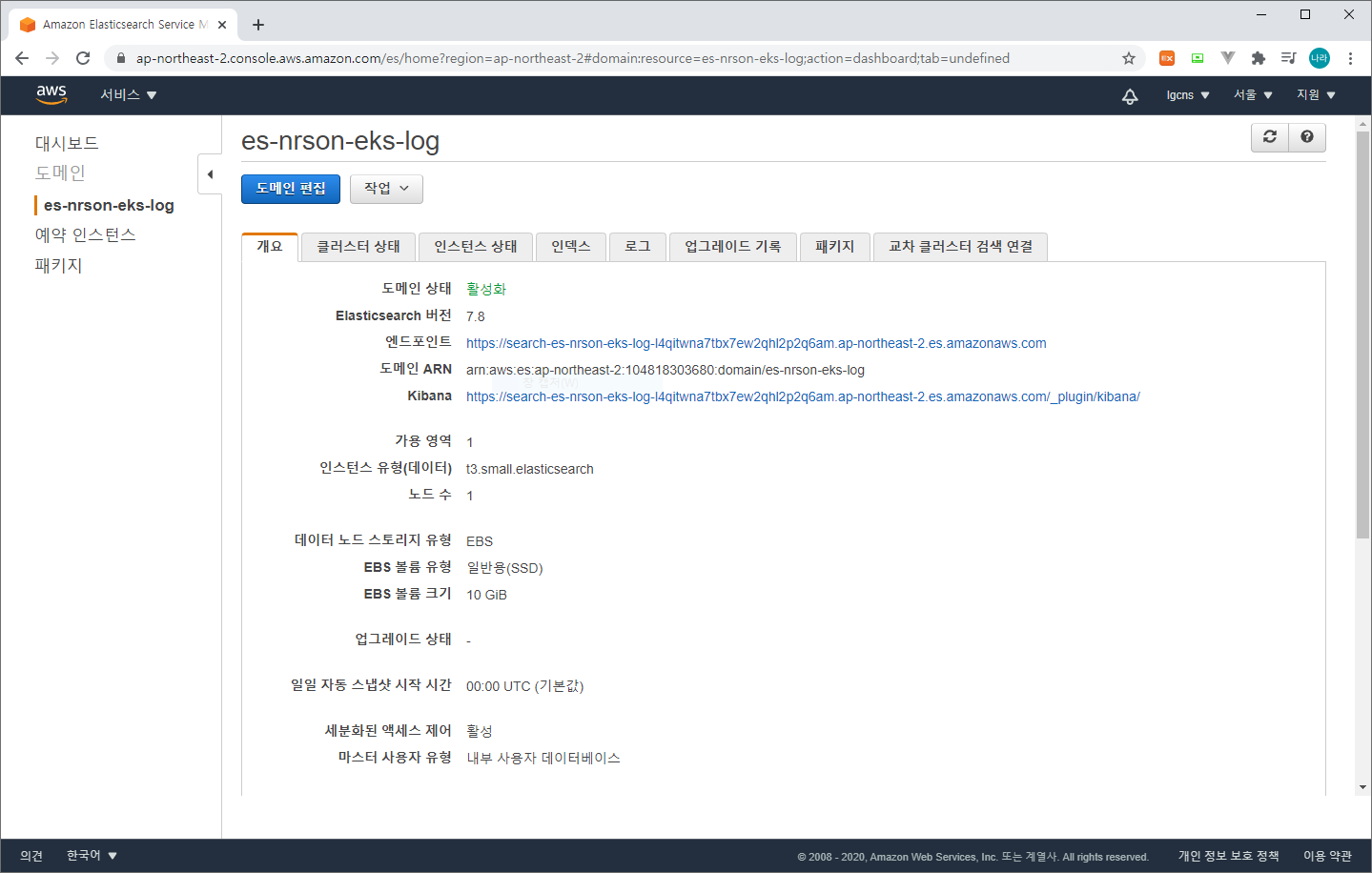
생성이 완료되면 다음과 같이 활성화 상태를 확인할 수 있다.
CloudWatch 구성
다음으로 CloudWatch에 수집된 로그를 ElasticSearch 저장소로 전송하기 위한 구성을 진행한다.
1) Policy & Role 생성
먼저 아래와 같이 앞서 생성한 es-nrson-eks-log ElasticSearch Service Domain에 로그를 전송하기 위한 Policy를 생성한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"es:*"
],
"Effect": "Allow",
"Resource": "arn:aws:es:ap-northeast-2:104818303680:domain/es-nrson-eks-log/*"
}
]
}생성한 Policy를 기반으로 아래와 같이 Lambda 기반 Role을 생성한다.
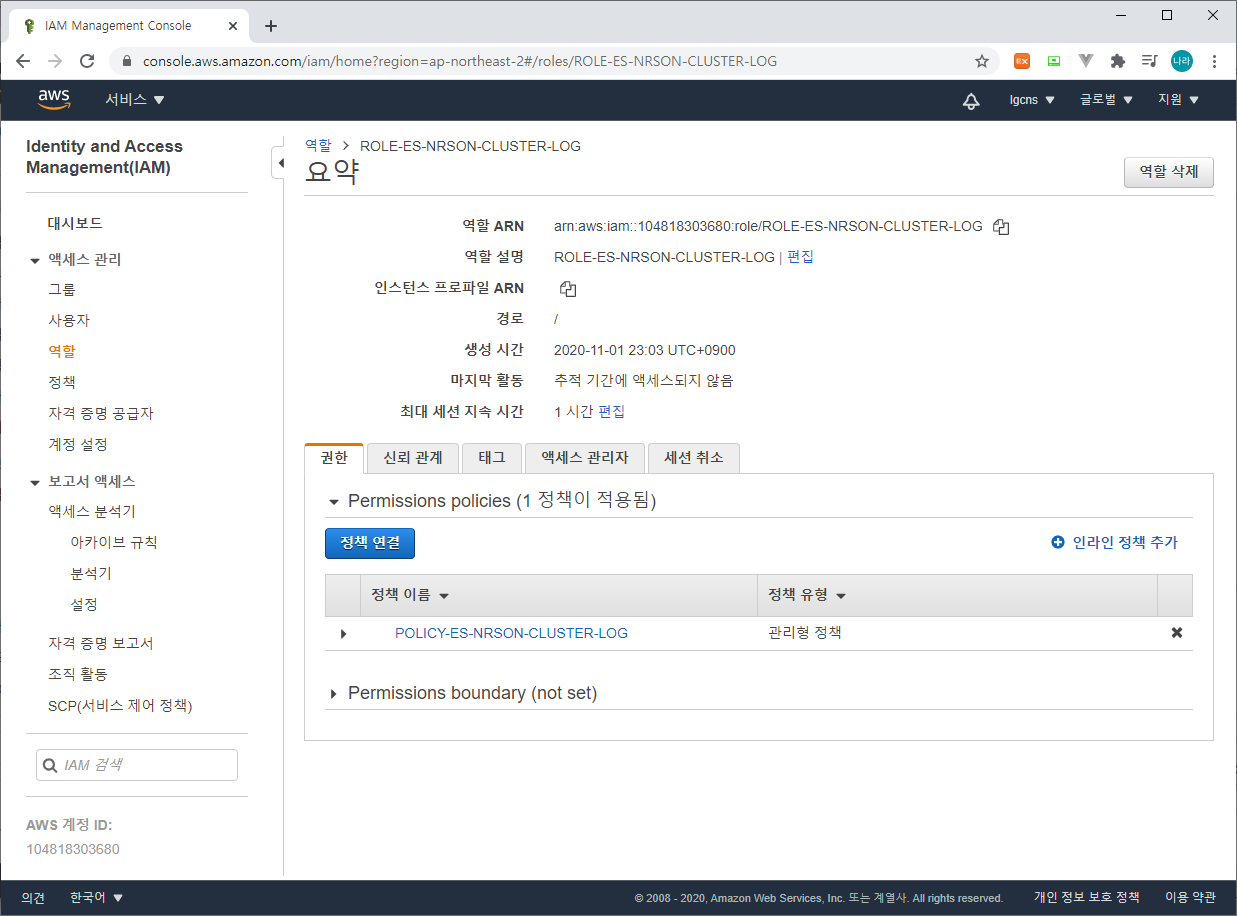
다음으로 해당 Role을 기반으로 ElasticSearch Subscription Filter를 생성한다.

CloudWatch의 구독 필터를 생성할 로그 그룹을 선택하고 작업 > ElasticSearch 구독 필터 생성을 선택한다.
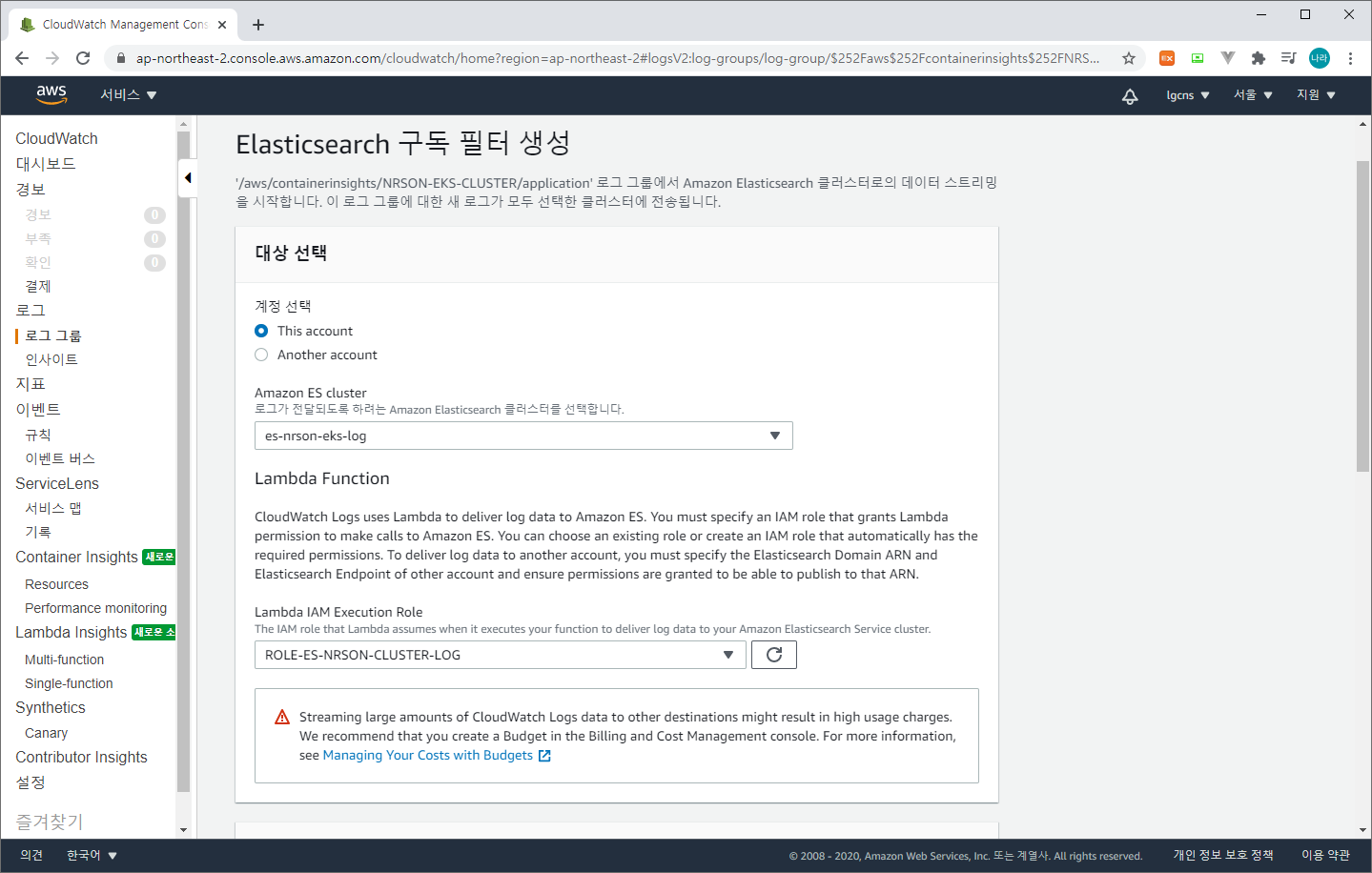
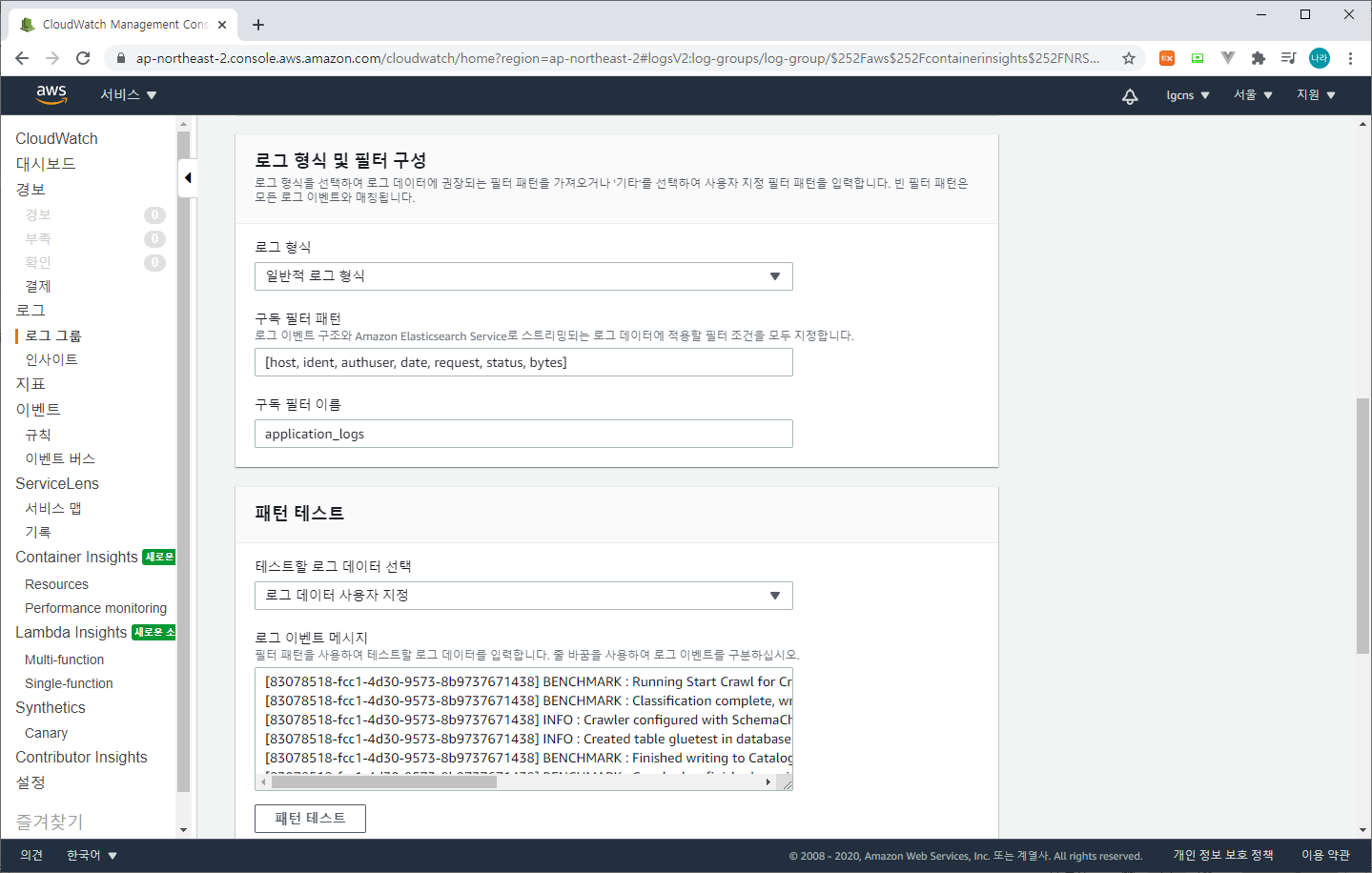
구독필터에는 앞서 생성한 ElasticSearch Domain과 Lambda IAM Role을 선택한다. 로그 형식 및 필터는 일반적인 로그 형식을 선택한 후 스트리밍을 시작한다.
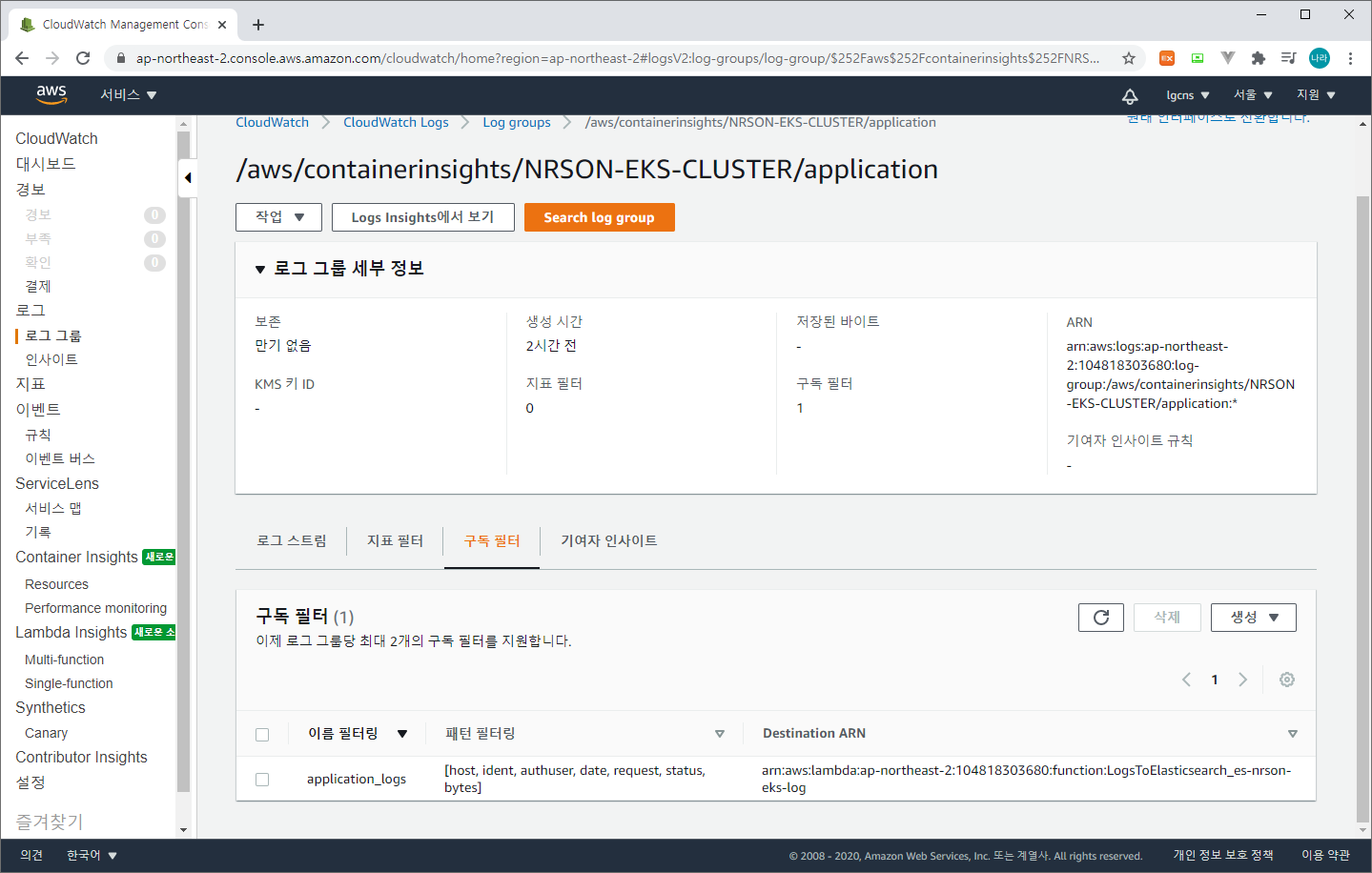
마지막으로 Kibana에 접속하여 수집되는 로그를 살펴보도록 하자.
Kibana 모니터링
Kibana는 앞서 생성한 ElasticSearch Domain을 통해 확인할 수 있다.

Kibana URL을 클릭하여 접속할 수 있으며, ID/PASSWORD는 Domain 생성 시 입력한 값이다.
1) Kibana 접속
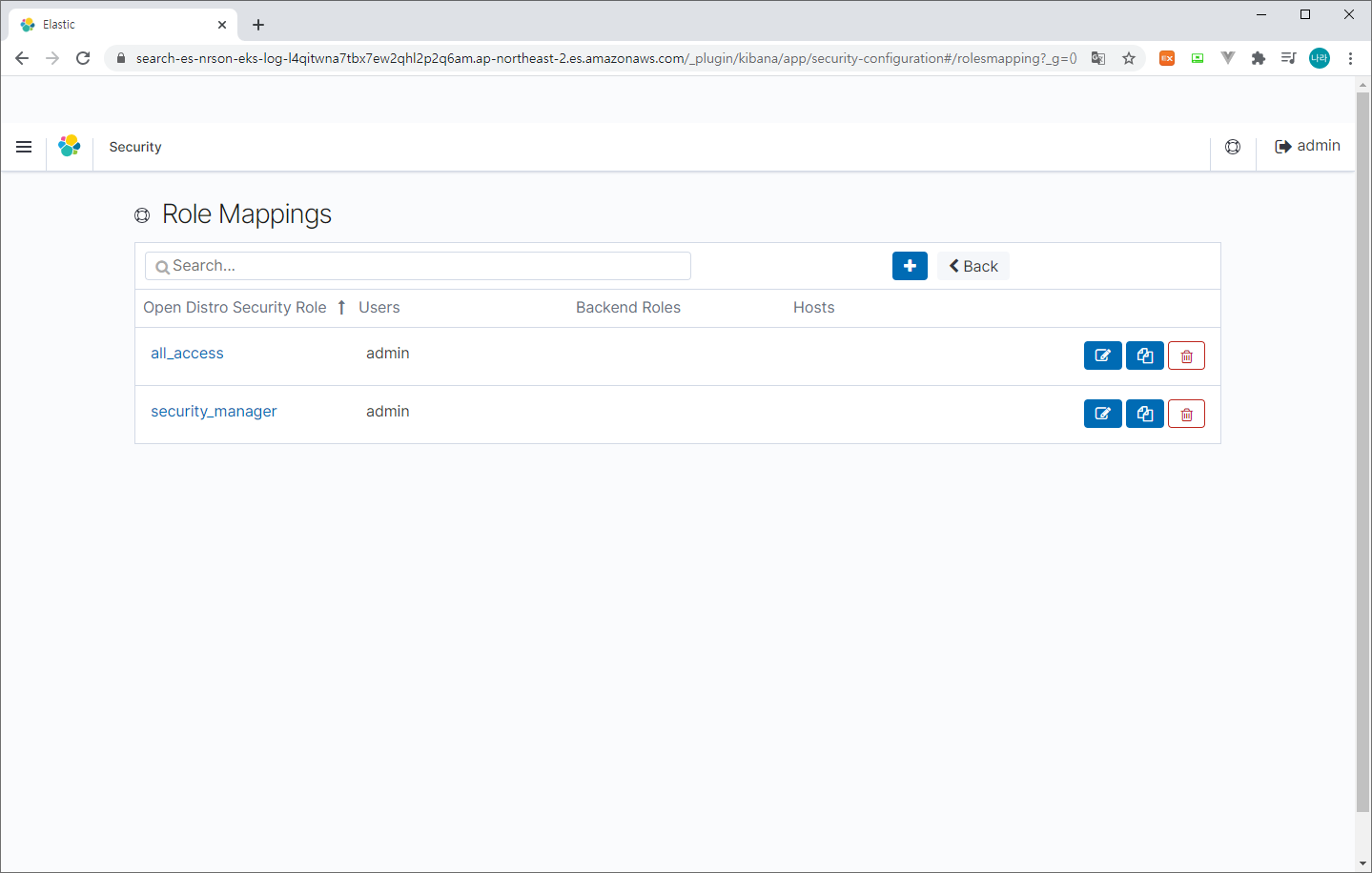
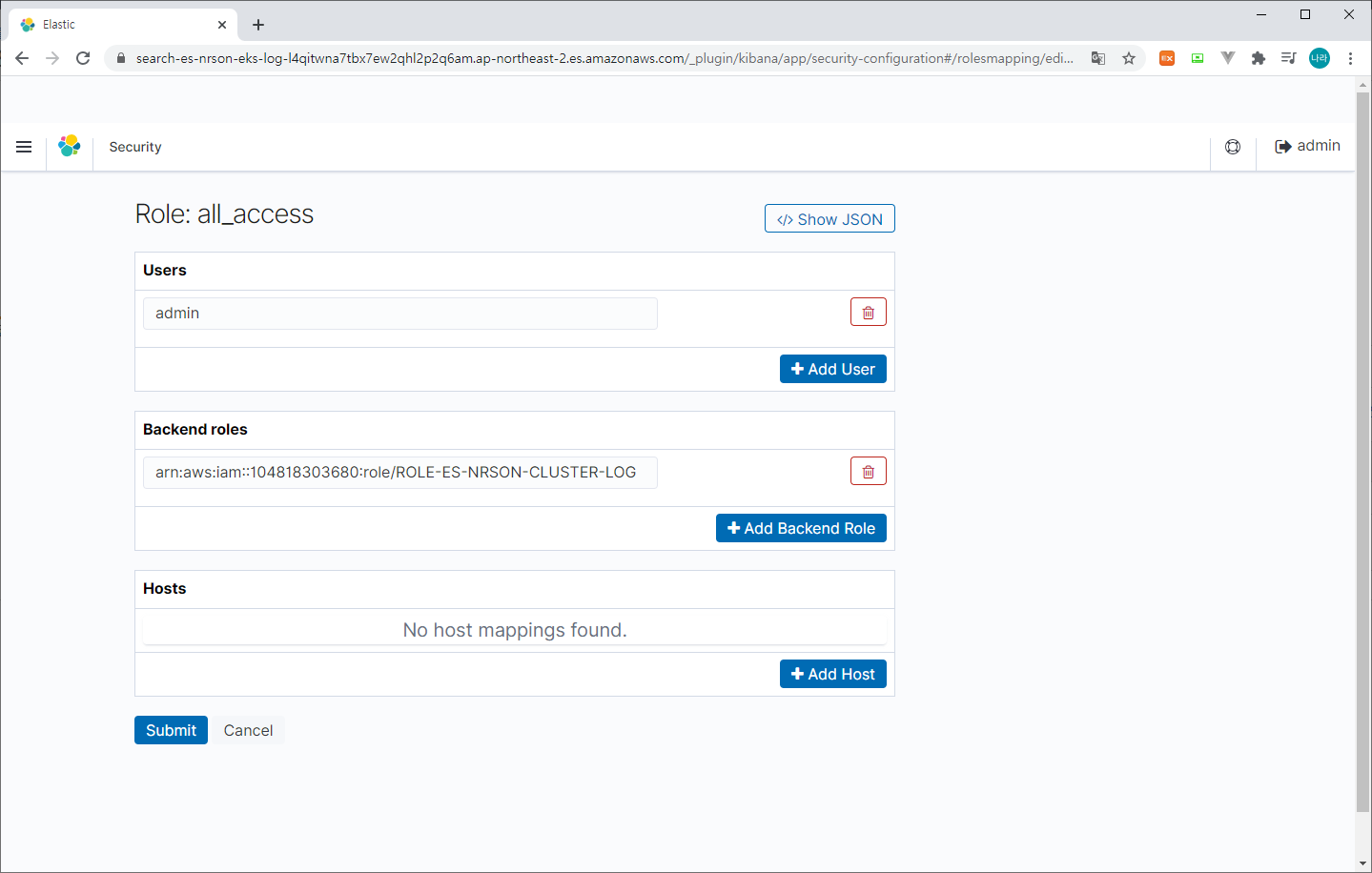
2) Security 접속

> Role Mappings & all_access 선택 후 앞서 생성한 Lambda Role 맵핑 (Backend roles)

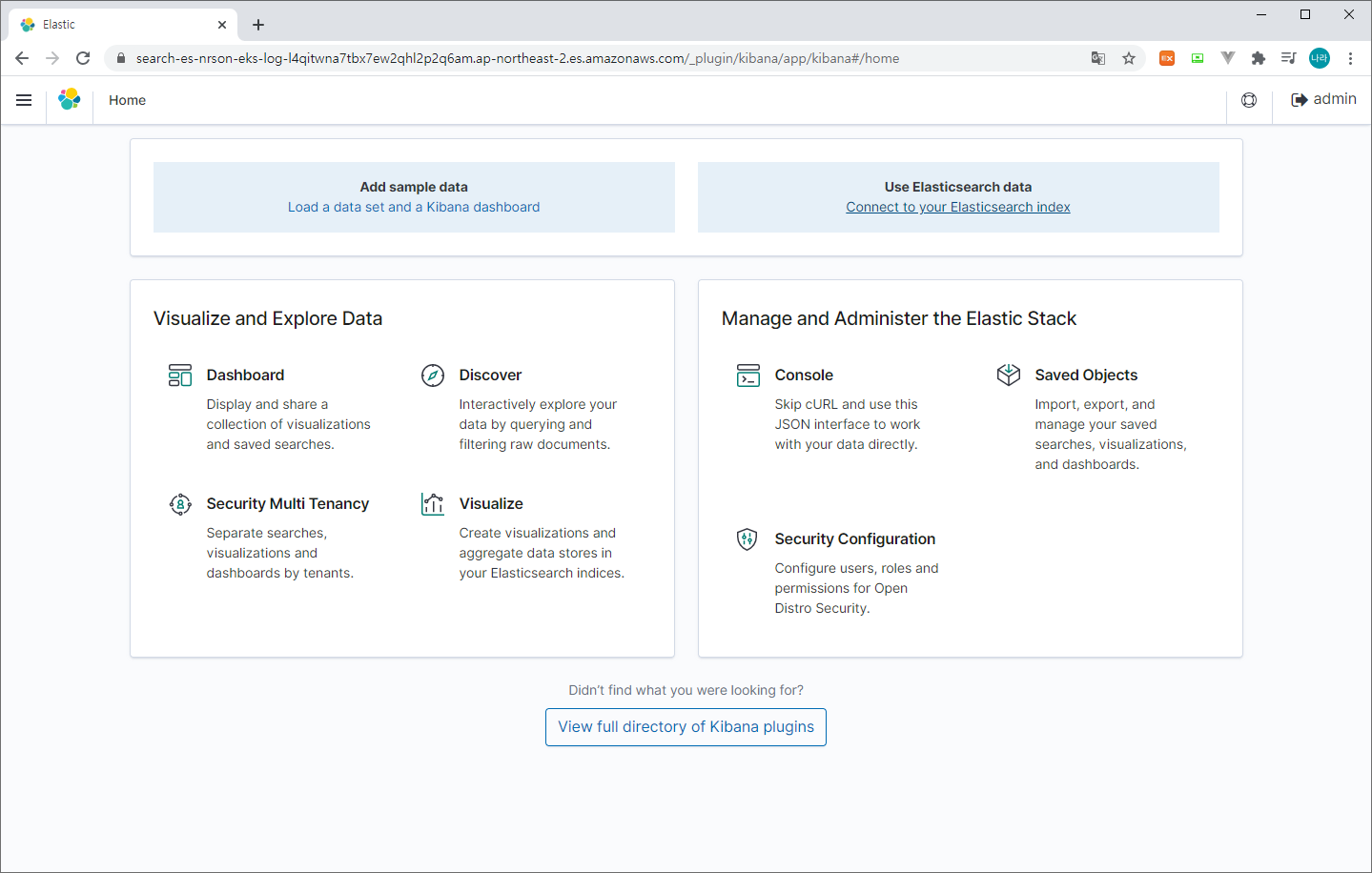
3) 대시보드 홈
> Use ElasticSearch Data (Connect to your ElasticSearch Index) 클릭
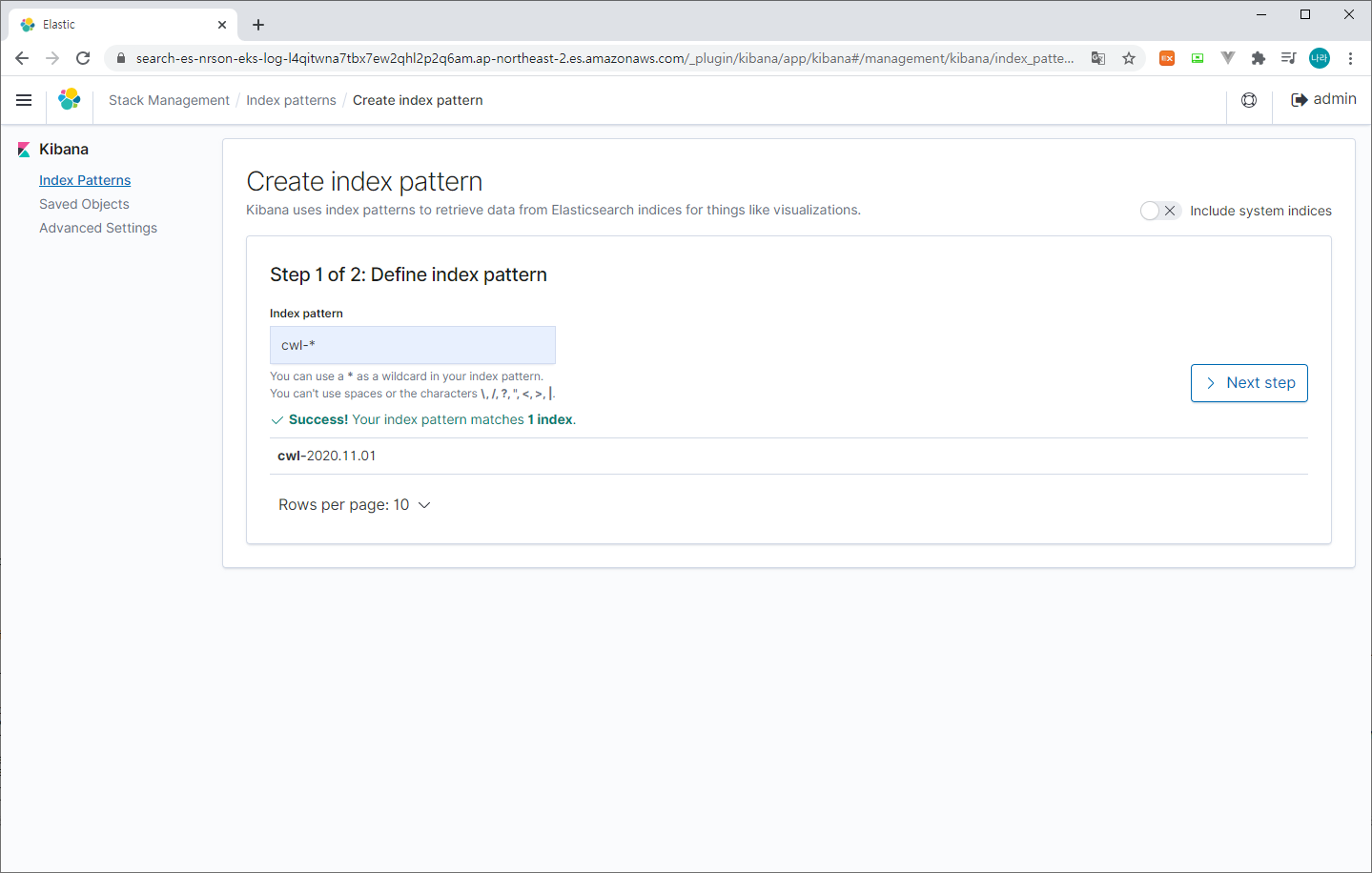
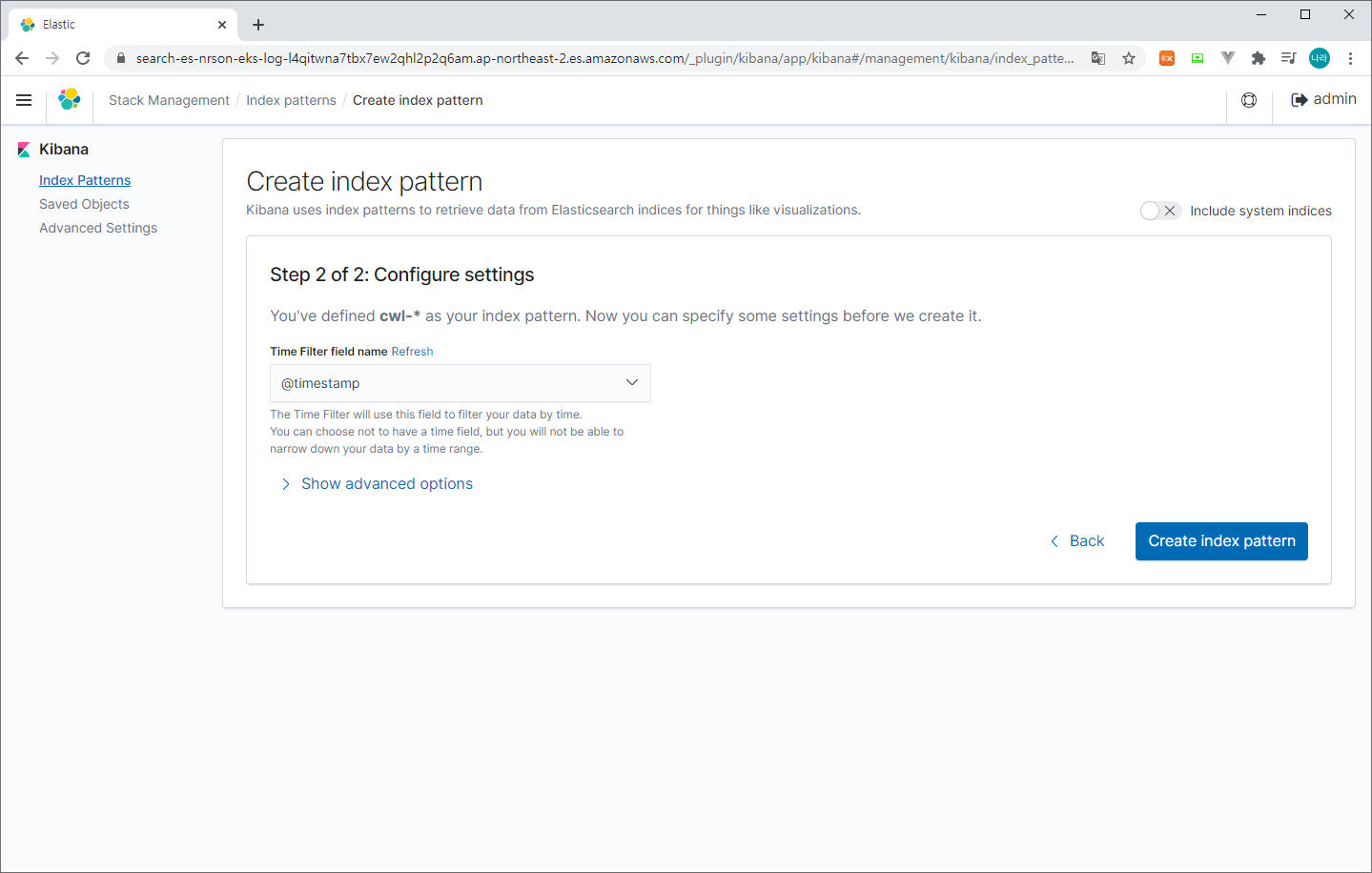
> Create index pattern (cwl-* 입력 > @timestamp > Create index pattern 선택)
4) Discover

> 수집된 로그 확인
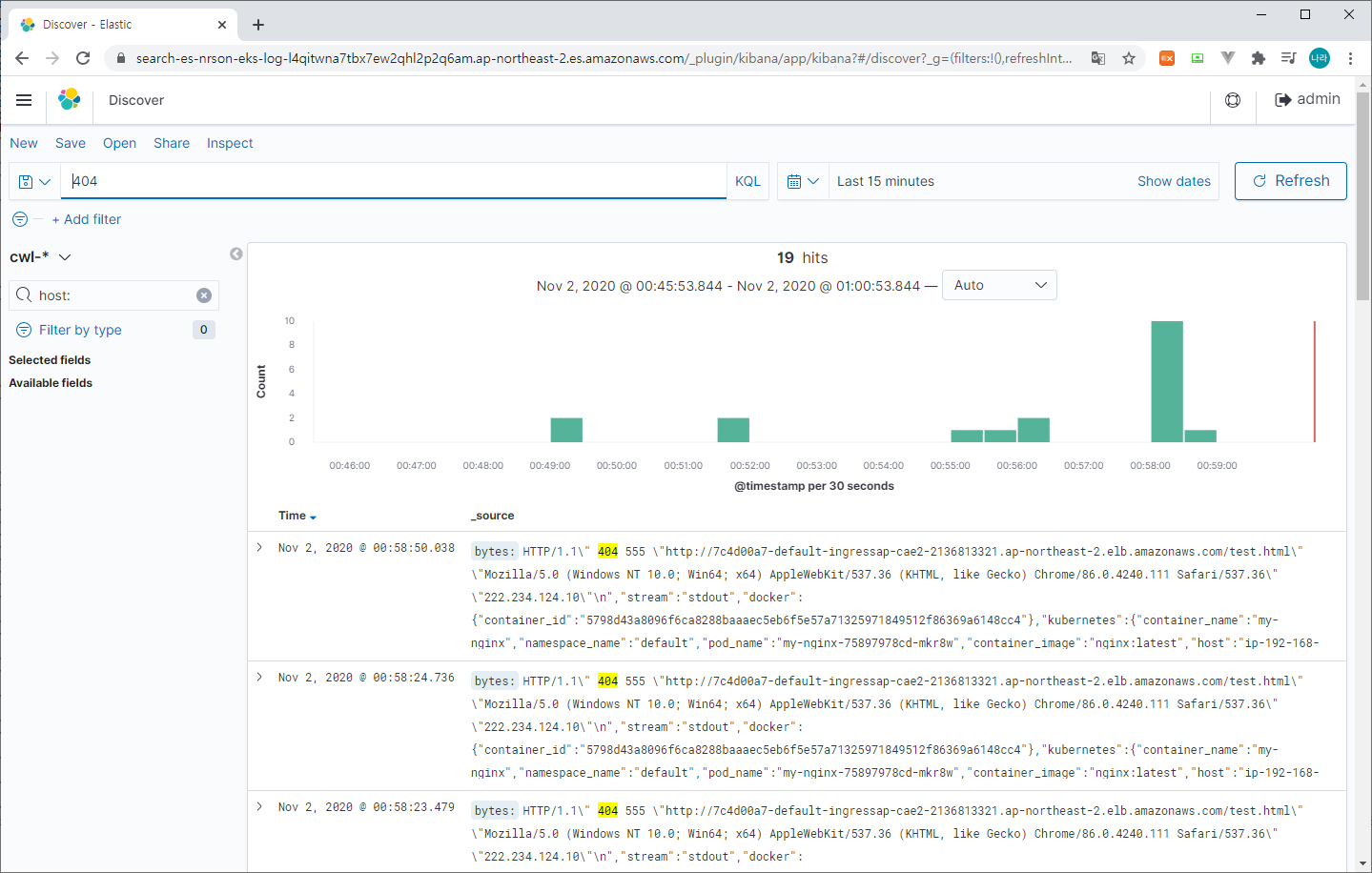
수집된 로그를 확인하는 방법은 간단하다. 모든 로그를 확인하거나 원하는 필터를 걸어 로그를 조회할 수 있다. 위는 404로 조회한 로그의 결과이다.
결론
지금까지 Amazon ElasticSearch 서비스를 사용하여 EKS에서 발생하는 로그를 수집하는 방법에 대해 살펴보았다. 사실 현재까지 구현된 환경은 로그를 Aggregation하는 수준에 그치며 이 로그를 어떻게 활용할 것인가에 대한 고민이 전혀 이루어지지 않았다고 볼 수 있다.
예를 들어 복잡하고 수많은 마이크로서비스 로그를 하나로 수집한다는 것 자체에 의미를 부여할수도 있지만, 이러한 로그를 여전히 하나하나 조회하여 검색하는 것이 얼마나 비효율적인지는 오래 IT일을 해 온 사람이라면 누구나 공감하는 할 것이다.
따라서 이를 보다 효과적으로 표출할 수 있는 표준 로깅 체계를 수립하여 검색 조건을 정렬하는 것이 좋다. 표준 로깅 체계를 수립함과 동시에 TraceID와 연계하기 위해 Spring Boot 기반 Sleuth나 Spring Framework 기반 Brave 등과 연계하는 것 역시 추천한다. 이를 통해 하나의 Transaction만 별도로 조회해 볼 수 있다. 예를 들어 TraceID 기반으로 Zipkin 또는 앞서 다루었던 AWS X-Ray를 통해 특정 TraceID의 문제를 감지하였다면, 이 ID를 기반으로 Kibana에서 조회하여 로그를 확인해 보는 방식이다.
'③ 클라우드 > ⓐ AWS' 카테고리의 다른 글
| Oracle DB AWS 환경에서 관리하기 - Amazon RDS (0) | 2020.11.10 |
|---|---|
| AWS 완전관리형 서비스로 Kafka 서비스 이용하기 (0) | 2020.11.07 |
| AWS 리소스 및 애플리케이션 모니터링 서비스 (CloudWatch) (0) | 2020.10.30 |
| 복잡한 마이크로서비스 관계 AWS X-Ray로 정리하자. (0) | 2020.10.26 |
| Lambda로 잊기 쉬운일을 예약하자! (EC2 자동 기동 종료 방법) (0) | 2020.10.20 |
- Total
- Today
- Yesterday
- API Gateway
- Docker
- jeus
- OpenStack
- openstack tenant
- JEUS7
- openstack token issue
- Da
- webtob
- apache
- aa
- aws
- TA
- JEUS6
- SA
- 쿠버네티스
- 마이크로서비스
- 아키텍처
- nodejs
- 마이크로서비스 아키텍처
- JBoss
- kubernetes
- MSA
- 오픈스택
- git
- k8s
- Architecture
- SWA
- wildfly
- node.js
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |