
티스토리 뷰
서론
본 포스팅에서는 Prometheus와 Grafana를 활용하여 분산트랜잭션 환경에서 반드시 필요한 모니터링 방법에 대해 살펴보도록 하겠습니다.
특히 Kubernetes 환경에서 yaml 파일을 관리하고 배포를 관리하는 Helm Chart를 활용하여 배포하는 방법에 대해 알아보겠습니다.
본론
먼저 Helm Chart에 대해 간단히 살펴보고 설치를 진행하도록 하겠습니다.
Helm Chart는 Kubernetes의 패키지 매니저 역할을 담당합니다. Chart라는 단위를 통해 Kubernetes Deployment를 관리하고 yaml파일을 등록하여 저장하는 저장소의 역할을 수행합니다.
대체로 Kubernetes를 통해 컨테이너 환경과 분산트랜잭션 환경을 구성하는데 가장 어려움을 느끼는 부분이 바로 Dockerfile이나 yaml 파일과 같은 환경 파일을 작성하는데 어려움이 있다는 점입니다.
대부분의 운영자, 개발자는 yaml 파일을 작성하기 시작하면서 부터 포기하는 경우가 많이 있습니다.
저 역시 3년 전.. 처음 접할때 yaml 파일을 보고 이건 대체 뭐지 하면서.. 어려움을 느낀 경험도 있었구요..
Helm에서 제공하는 Repository는 github에 등록되어 있습니다. 공개되어 있어 누구나 다운로드를 받을 수 있습니다.
[root@kubemaster ~]# git clone https://github.com/helm/charts.git
Cloning into 'charts'...
remote: Enumerating objects: 20, done.
remote: Counting objects: 100% (20/20), done.
remote: Compressing objects: 100% (20/20), done.
remote: Total 101793 (delta 9), reused 0 (delta 0), pack-reused 101773
Receiving objects: 100% (101793/101793), 27.70 MiB | 8.13 MiB/s, done.
Resolving deltas: 100% (75670/75670), done.
[root@kubemaster ~]#위와 같이 다운로드를 받으면 아래와 같이 chart repo를 확인할 수 있으며, chart에는 stable, incubator, test version으로 각각 다양한 Package들이 제공됩니다.
대체로 Helm에서는 stable로 제공되는 안정된 버전의 Chart를 활용하는 것을 권고합니다.
[root@kubemaster stable]# pwd
/root/charts/stable
[root@kubemaster stable]# ls
acs-engine-autoscaler coredns filebeat horovod kubernetes-dashboard msoms phabricator rethinkdb sumologic-fluentd
aerospike cosbench fluent-bit hubot kuberos mssql-linux phpbb risk-advisor superset
airflow coscale fluentd ignite kube-slack mysql phpmyadmin rocketchat swift
ambassador couchbase-operator fluentd-elasticsearch inbucket kube-state-metrics mysqldump pomerium rookout sysdig
anchore-engine couchdb g2 influxdb kubewatch namerd postgresql sapho telegraf
apm-server dask gangway ingressmonitorcontroller kured nats prestashop satisfy tensorflow-notebook
ark dask-distributed gce-ingress instana-agent lamp neo4j presto schema-registry-ui tensorflow-serving
artifactory datadog gcloud-endpoints ipfs linkerd newrelic-infrastructure prisma sealed-secrets terracotta
artifactory-ha dex gcloud-sqlproxy jaeger-operator locust nextcloud prometheus searchlight testlink
atlantis distributed-jmeter gcp-night-king janusgraph logdna-agent nfs-client-provisioner prometheus-adapter selenium tomcat
auditbeat distributed-tensorflow ghost jasperreports logstash nfs-server-provisioner prometheus-blackbox-exporter sematext-agent traefik
aws-cluster-autoscaler distribution gitlab-ce jenkins luigi nginx-ingress prometheus-cloudwatch-exporter sematext-docker-agent uchiwa
aws-iam-authenticator dmarc2logstash gitlab-ee joomla magento nginx-ldapauth-proxy prometheus-consul-exporter sensu unbound
bitcoind docker-registry gocd k8s-spot-rescheduler magic-ip-address nginx-lego prometheus-couchdb-exporter sentry unifi
bookstack dokuwiki goldpinger k8s-spot-termination-handler magic-namespace node-problem-detector prometheus-mongodb-exporter seq vault-operator
buildkite drone grafana kafka-manager mailhog node-red prometheus-mysql-exporter signalfx-agent velero
burrow drupal graphite kanister-operator mariadb oauth2-proxy prometheus-nats-exporter signalsciences verdaccio
centrifugo efs-provisioner graylog kapacitor mattermost-team-edition odoo prometheus-node-exporter socat-tunneller voyager
cerebro elastabot hackmd karma mcrouter opa prometheus-operator sonarqube vsphere-cpi
cert-manager elastalert hadoop katafygio mediawiki opencart prometheus-postgres-exporter sonatype-nexus wavefront
chaoskube elasticsearch hazelcast keel memcached openebs prometheus-pushgateway spark weave-cloud
chartmuseum elasticsearch-curator hazelcast-jet keycloak mercure openiban prometheus-rabbitmq-exporter spark-history-server weave-scope
chronograf elasticsearch-exporter heapster kiam metabase openldap prometheus-redis-exporter spartakus wordpress
clamav elastic-stack heartbeat kibana metallb openvpn prometheus-snmp-exporter spinnaker xray
cloudserver envoy helm-exporter kong metricbeat orangehrm prometheus-to-sd spotify-docker-gc zeppelin
cluster-autoscaler etcd-operator hl-composer kube2iam metrics-server osclass quassel spring-cloud-data-flow zetcd
cluster-overprovisioner ethereum hlf-ca kubed minecraft owncloud rabbitmq stackdriver-exporter
cockroachdb eventrouter hlf-couchdb kubedb minio pachyderm rabbitmq-ha stash
collabora-code express-gateway hlf-ord kube-hunter mission-control parse redis stellar-core
concourse external-dns hlf-peer kube-lego mongodb percona redis-ha stolon
consul factorio hoard kube-ops-view mongodb-replicaset percona-xtradb-cluster redmine suitecrm
contour falco home-assistant kuberhealthy moodle pgadmin reloader sumokube
[root@kubemaster stable]# 위와 같이 stable 버전으로 제공되는 다양한 Package 중 Prometheus와 Grafana에 대한 구성을 진행해 보겠습니다.
여기서 활용할 패키지는 총 4개로 다음과 같습니다.
[root@kubemaster myhelm]# ls -al
total 4
drwxr-xr-x. 6 root root 132 Mar 3 21:26 .
drwxr-xr-x. 6 root root 68 Mar 3 17:26 ..
drwxr-xr-x. 5 root root 138 Mar 3 17:27 grafana
drwxr-xr-x. 3 root root 110 Mar 3 17:27 kube-state-metrics
drwxr-xr-x. 3 root root 110 Mar 3 17:27 prometheus-node-exporter
drwxr-xr-x. 7 root root 269 Mar 3 17:29 prometheus-operator
[root@kubemaster myhelm]# 하나의 Chart는 templates와 values 그리고 다시 chart로 구성되어 있습니다.
- templates : Kubernetes Deployment, Service 등의 Kubernetes Object들의 템플릿들을 정의해 놓은 yaml 파일들
- values.yaml : template의 yaml 파일들에 적용할 변수화해놓은 변수들을 넣어줄 파일
- chart : 해당 chart에서 사용할 외부 chart 즉 참조해야 하는 라이브러리 파일
즉 하나의 Chart를 등록하기 위해서는 templates에 정의 된 yaml 파일을 커스터마이징하기 위해 values.yaml 파일을 수정하며, chart 디렉토리에 참조해야 할 라이브러리들 즉 또 다른 Chart의 패키징된 파일을 저장해야 합니다.

Helm은 Client-Server 구조를 취하고 있습니다. 사용자가 사용하는 CLI가 helm이고 실제로 Kubernetes에서 배포를 하고 관리하는 서버는 tiller라고 부릅니다. 그래서 사용자는 우선 Helm을 로컬에 설치하고 tiller를 서버에 배포해서 사용하게 됩니다.
Helm은 Kubernetes 설치 시 Kubespray의 addons 중 하나로 지정하여 손쉽게 설치할 수 있습니다.
물론 수동으로 설치할 수도 있으며, 이때는 helm과 tiller를 함께 설치하여 수동으로 구성해 주어야 합니다.
helm 자체를 설치하는 방법은 워낙 많은 포스팅에서 제공되고 있으니 언급하지 않고 활용 방법에 대해서만 살펴보겠습니다.
앞서 다운로드 받은 helm package 중 grafana, kube-state-metrics, prometheus-node-exporter, prometheus-operator package를 특정 공간에 복사하고 이를 커스터 마이징하여 Chart를 등록해 보도록 하겠습니다.
1) Chart 관리
Chart에서 values.yaml 파일은 yaml 파일에 저장되는 변수의 집합이라고 앞서 살펴보았습니다.
여기서 수정해야 할 부분은 node에 부여되는 label들에 대한 nodeSelector를 지정하여 Prometheus와 Grafana Pod가 특정 서버에 배치될 수 있도록 구성하는 것입니다.
먼저 현재 Node의 Label은 다음과 같습니다.
[root@kubemaster charts]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
kubemaster Ready master 6h33m v1.16.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kubemaster,kubernetes.io/os=linux,node-role.kubernetes.io/master=
kubeworker1 Ready <none> 6h32m v1.16.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,key=monitoring,kubernetes.io/arch=amd64,kubernetes.io/hostname=kubeworker1,kubernetes.io/os=linux
kubeworker2 Ready <none> 6h32m v1.16.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kubeworker2,kubernetes.io/os=linux
[root@kubemaster charts]# 이 중 kubeworker1에만 등록되어 있는 key=monitoring이라는 label을 기반으로 Prometheus와 Grafana를 배치해 보도록 하겠습니다.
[root@kubemaster myhelm]# grep -i '^\ *nodeselector' -A 1 -B 1 grafana/values.yaml
#
nodeSelector:
key: monitoring
[root@kubemaster myhelm]# grep -i '^\ *nodeselector' -A 1 -B 1 kube-state-metrics/values.yaml
## Ref: https://kubernetes.io/docs/user-guide/node-selection/
nodeSelector:
key: monitoring
[root@kubemaster myhelm]# grep -i '^\ *nodeselector' -A 1 -B 1 prometheus-node-exporter/values.yaml
##
nodeSelector: {}
# beta.kubernetes.io/arch: amd64
[root@kubemaster myhelm]# grep -i '^\ *nodeselector' -A 1 -B 1 prometheus-operator/values.yaml
##
nodeSelector:
key: monitoring
--
podAnnotations: {}
nodeSelector:
key: monitoring
--
##
nodeSelector:
key: monitoring
--
##
nodeSelector:
key: monitoring
[root@kubemaster myhelm]# 위와 같이 grafana, kube-state-metrics, prometheus-node-exporter, prometheus-operator에 대한 volues.yaml을 각각 수정합니다.
모든 nodeSelector에 대한 value를 key: monitoring으로 변경하되 prometheus-node-exporter는 모든 모니터링해야 하는 노드에 배치되어야 하므로 수정없이 nodeSelector: {}를 유지합니다.
values.yaml 파일의 수정이 완료되었으면, 다음으로 prometheus-operator가 Chart를 등록할 때 참조해야 하는 grafana, kube-state-metrics, prometheus-node-exporter에 대한 package를 수행하여 charts 디렉토리에 추가합니다.
[root@kubemaster myhelm]# helm package grafana/
Successfully packaged chart and saved it to: /root/git_repo/myhelm/grafana-5.0.4.tgz
[root@kubemaster myhelm]# helm package kube-state-metrics/
Successfully packaged chart and saved it to: /root/git_repo/myhelm/kube-state-metrics-2.7.1.tgz
[root@kubemaster myhelm]# helm package prometheus-node-exporter/
Successfully packaged chart and saved it to: /root/git_repo/myhelm/prometheus-node-exporter-1.9.0.tgz
[root@kubemaster myhelm]# mv *.tgz prometheus-operator/charts/
[root@kubemaster myhelm]# ls -la prometheus-operator/charts/
total 36
drwxr-xr-x. 2 root root 109 Mar 3 21:26 .
drwxr-xr-x. 7 root root 269 Mar 3 17:29 ..
-rw-r--r--. 1 root root 19298 Mar 3 21:26 grafana-5.0.4.tgz
-rw-r--r--. 1 root root 6653 Mar 3 21:26 kube-state-metrics-2.7.1.tgz
-rw-r--r--. 1 root root 6571 Mar 3 21:26 prometheus-node-exporter-1.9.0.tgz
[root@kubemaster myhelm]#위와 같이 helm package로 chart를 packaging하고 이를 charts 디렉토리로 move 시킵니다.
2) Prometheus chart 설치
chart를 등록하기 이전에 grafana와 prometheus alertmanage가 사용하는 pv.yaml을 등록합니다.
[root@kubemaster myhelm]# cat pv-monitoring.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-for-alertmanager
spec:
capacity:
storage: 50Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/nfs/alertmanager
server: 192.168.56.102
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-for-grafana
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/nfs/grafana
server: 192.168.56.102
[root@kubemaster myhelm]#kubectl create -f pv.yaml 을 등록하면 아래와 같이 pv를 확인할 수 있습니다.
[root@kubemaster myhelm]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-for-alertmanager 50Gi RWO Retain Available 3h56m
pv-for-grafana 10Gi RWO Retain Available 3h56m
[root@kubemaster myhelm]#이제 helm install을 활용하여 helm chart를 등록해 보도록 하겠습니다.
(helm install --name [chart_name] --namespace [namespace] [chart_path])
[root@kubemaster prometheus-operator]# pwd
/root/git_repo/myhelm/prometheus-operator
[root@kubemaster prometheus-operator]# helm install --name prometheus --namespace monitoring .
NAME: prometheus
LAST DEPLOYED: Tue Mar 3 21:32:02 2020
NAMESPACE: monitoring
STATUS: DEPLOYED
RESOURCES:
==> v1/Alertmanager
NAME AGE
prometheus-prometheus-oper-alertmanager 31s
==> v1/ClusterRole
NAME AGE
prometheus-grafana-clusterrole 32s
prometheus-prometheus-oper-operator 32s
prometheus-prometheus-oper-operator-psp 32s
prometheus-prometheus-oper-prometheus 32s
prometheus-prometheus-oper-prometheus-psp 32s
psp-prometheus-kube-state-metrics 32s
psp-prometheus-prometheus-node-exporter 32s
==> v1/ClusterRoleBinding
NAME AGE
prometheus-grafana-clusterrolebinding 32s
prometheus-prometheus-oper-operator 32s
prometheus-prometheus-oper-operator-psp 32s
prometheus-prometheus-oper-prometheus 32s
prometheus-prometheus-oper-prometheus-psp 32s
psp-prometheus-kube-state-metrics 32s
psp-prometheus-prometheus-node-exporter 32s
==> v1/ConfigMap
NAME DATA AGE
prometheus-grafana 1 32s
prometheus-grafana-config-dashboards 1 32s
prometheus-grafana-test 1 32s
prometheus-prometheus-oper-apiserver 1 32s
prometheus-prometheus-oper-cluster-total 1 32s
prometheus-prometheus-oper-controller-manager 1 32s
prometheus-prometheus-oper-etcd 1 32s
prometheus-prometheus-oper-grafana-datasource 1 32s
prometheus-prometheus-oper-k8s-coredns 1 32s
prometheus-prometheus-oper-k8s-resources-cluster 1 32s
prometheus-prometheus-oper-k8s-resources-namespace 1 32s
prometheus-prometheus-oper-k8s-resources-node 1 32s
prometheus-prometheus-oper-k8s-resources-pod 1 32s
prometheus-prometheus-oper-k8s-resources-workload 1 32s
prometheus-prometheus-oper-k8s-resources-workloads-namespace 1 32s
prometheus-prometheus-oper-kubelet 1 32s
prometheus-prometheus-oper-namespace-by-pod 1 32s
prometheus-prometheus-oper-namespace-by-workload 1 32s
prometheus-prometheus-oper-node-cluster-rsrc-use 1 32s
prometheus-prometheus-oper-node-rsrc-use 1 32s
prometheus-prometheus-oper-nodes 1 32s
prometheus-prometheus-oper-persistentvolumesusage 1 32s
prometheus-prometheus-oper-pod-total 1 32s
prometheus-prometheus-oper-pods 1 32s
prometheus-prometheus-oper-prometheus 1 32s
prometheus-prometheus-oper-proxy 1 32s
prometheus-prometheus-oper-scheduler 1 32s
prometheus-prometheus-oper-statefulset 1 32s
prometheus-prometheus-oper-workload-total 1 32s
==> v1/DaemonSet
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
prometheus-prometheus-node-exporter 3 3 3 3 3 <none> 31s
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-grafana 1/1 1 1 31s
prometheus-kube-state-metrics 1/1 1 1 31s
prometheus-prometheus-oper-operator 1/1 1 1 31s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
prometheus-grafana-58d5bbf9f4-dkqxm 3/3 Running 0 31s
prometheus-kube-state-metrics-556f95ff74-ghb92 1/1 Running 0 31s
prometheus-prometheus-node-exporter-2tkzw 1/1 Running 0 31s
prometheus-prometheus-node-exporter-qmnhh 1/1 Running 0 31s
prometheus-prometheus-node-exporter-s4cbk 1/1 Running 0 31s
prometheus-prometheus-oper-operator-78595b64c-8fqxl 2/2 Running 0 31s
==> v1/Prometheus
NAME AGE
prometheus-prometheus-oper-prometheus 31s
==> v1/PrometheusRule
NAME AGE
prometheus-prometheus-oper-alertmanager.rules 30s
prometheus-prometheus-oper-etcd 30s
prometheus-prometheus-oper-general.rules 30s
prometheus-prometheus-oper-k8s.rules 30s
prometheus-prometheus-oper-kube-apiserver-error 30s
prometheus-prometheus-oper-kube-apiserver.rules 30s
prometheus-prometheus-oper-kube-prometheus-node-recording.rules 30s
prometheus-prometheus-oper-kube-scheduler.rules 30s
prometheus-prometheus-oper-kubernetes-absent 30s
prometheus-prometheus-oper-kubernetes-apps 30s
prometheus-prometheus-oper-kubernetes-resources 30s
prometheus-prometheus-oper-kubernetes-storage 30s
prometheus-prometheus-oper-kubernetes-system 30s
prometheus-prometheus-oper-kubernetes-system-apiserver 30s
prometheus-prometheus-oper-kubernetes-system-controller-manager 30s
prometheus-prometheus-oper-kubernetes-system-kubelet 30s
prometheus-prometheus-oper-kubernetes-system-scheduler 30s
prometheus-prometheus-oper-node-exporter 30s
prometheus-prometheus-oper-node-exporter.rules 30s
prometheus-prometheus-oper-node-network 30s
prometheus-prometheus-oper-node-time 30s
prometheus-prometheus-oper-node.rules 30s
prometheus-prometheus-oper-prometheus 30s
prometheus-prometheus-oper-prometheus-operator 30s
==> v1/Role
NAME AGE
prometheus-grafana-test 32s
prometheus-prometheus-oper-alertmanager 32s
==> v1/RoleBinding
NAME AGE
prometheus-grafana-test 32s
prometheus-prometheus-oper-alertmanager 32s
==> v1/Secret
NAME TYPE DATA AGE
alertmanager-prometheus-prometheus-oper-alertmanager Opaque 1 32s
prometheus-grafana Opaque 3 32s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-grafana ClusterIP 10.233.23.0 <none> 80/TCP 32s
prometheus-kube-state-metrics ClusterIP 10.233.4.171 <none> 8080/TCP 31s
prometheus-prometheus-node-exporter ClusterIP 10.233.54.30 <none> 9100/TCP 31s
prometheus-prometheus-oper-alertmanager ClusterIP 10.233.29.188 <none> 9093/TCP 32s
prometheus-prometheus-oper-coredns ClusterIP None <none> 9153/TCP 32s
prometheus-prometheus-oper-kube-controller-manager ClusterIP None <none> 10252/TCP 32s
prometheus-prometheus-oper-kube-etcd ClusterIP None <none> 2379/TCP 32s
prometheus-prometheus-oper-kube-proxy ClusterIP None <none> 10249/TCP 32s
prometheus-prometheus-oper-kube-scheduler ClusterIP None <none> 10251/TCP 32s
prometheus-prometheus-oper-operator ClusterIP 10.233.9.20 <none> 8080/TCP,443/TCP 32s
prometheus-prometheus-oper-prometheus ClusterIP 10.233.8.84 <none> 9090/TCP 31s
==> v1/ServiceAccount
NAME SECRETS AGE
prometheus-grafana 1 32s
prometheus-grafana-test 1 32s
prometheus-kube-state-metrics 1 32s
prometheus-prometheus-node-exporter 1 32s
prometheus-prometheus-oper-alertmanager 1 32s
prometheus-prometheus-oper-operator 1 32s
prometheus-prometheus-oper-prometheus 1 32s
==> v1/ServiceMonitor
NAME AGE
prometheus-prometheus-oper-alertmanager 30s
prometheus-prometheus-oper-apiserver 30s
prometheus-prometheus-oper-coredns 30s
prometheus-prometheus-oper-grafana 30s
prometheus-prometheus-oper-kube-controller-manager 30s
prometheus-prometheus-oper-kube-etcd 30s
prometheus-prometheus-oper-kube-proxy 30s
prometheus-prometheus-oper-kube-scheduler 30s
prometheus-prometheus-oper-kube-state-metrics 30s
prometheus-prometheus-oper-kubelet 30s
prometheus-prometheus-oper-node-exporter 30s
prometheus-prometheus-oper-operator 30s
prometheus-prometheus-oper-prometheus 30s
==> v1beta1/ClusterRole
NAME AGE
prometheus-kube-state-metrics 32s
==> v1beta1/ClusterRoleBinding
NAME AGE
prometheus-kube-state-metrics 32s
==> v1beta1/MutatingWebhookConfiguration
NAME AGE
prometheus-prometheus-oper-admission 31s
==> v1beta1/PodSecurityPolicy
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES
prometheus-grafana false RunAsAny RunAsAny RunAsAny RunAsAny false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim
prometheus-grafana-test false RunAsAny RunAsAny RunAsAny RunAsAny false configMap,downwardAPI,emptyDir,projected,secret
prometheus-kube-state-metrics false RunAsAny MustRunAsNonRoot MustRunAs MustRunAs false secret
prometheus-prometheus-node-exporter false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim,hostPath
prometheus-prometheus-oper-alertmanager false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim
prometheus-prometheus-oper-operator false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim
prometheus-prometheus-oper-prometheus false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim
==> v1beta1/Role
NAME AGE
prometheus-grafana 32s
==> v1beta1/RoleBinding
NAME AGE
prometheus-grafana 32s
==> v1beta1/ValidatingWebhookConfiguration
NAME AGE
prometheus-prometheus-oper-admission 30s
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=prometheus"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
[root@kubemaster prometheus-operator]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
prometheus 1 Tue Mar 3 21:32:02 2020 DEPLOYED prometheus-operator-8.10.0 0.36.0 monitoring
[root@kubemaster prometheus-operator]# helm get notes prometheus
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=prometheus"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
[root@kubemaster prometheus-operator]#
위와 같이 chart install이 정상적으로 완료되면 helm list로 등록된 chart를 확인할 수 있습니다.
Kubernetes에 정상 배포되었는지 확인해 보도록 하겠습니다.
[root@kubemaster stable]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 2m37s
pod/prometheus-grafana-58d5bbf9f4-dkqxm 3/3 Running 0 2m42s
pod/prometheus-kube-state-metrics-556f95ff74-ghb92 1/1 Running 0 2m42s
pod/prometheus-prometheus-node-exporter-2tkzw 1/1 Running 0 2m42s
pod/prometheus-prometheus-node-exporter-qmnhh 1/1 Running 0 2m42s
pod/prometheus-prometheus-node-exporter-s4cbk 1/1 Running 0 2m42s
pod/prometheus-prometheus-oper-operator-78595b64c-8fqxl 2/2 Running 0 2m42s
pod/prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 2m26s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 2m37s
service/prometheus-grafana ClusterIP 10.233.23.0 <none> 80/TCP 2m43s
service/prometheus-kube-state-metrics ClusterIP 10.233.4.171 <none> 8080/TCP 2m42s
service/prometheus-operated ClusterIP None <none> 9090/TCP 2m26s
service/prometheus-prometheus-node-exporter ClusterIP 10.233.54.30 <none> 9100/TCP 2m42s
service/prometheus-prometheus-oper-alertmanager ClusterIP 10.233.29.188 <none> 9093/TCP 2m43s
service/prometheus-prometheus-oper-operator ClusterIP 10.233.9.20 <none> 8080/TCP,443/TCP 2m43s
service/prometheus-prometheus-oper-prometheus ClusterIP 10.233.8.84 <none> 9090/TCP 2m42s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-prometheus-node-exporter 3 3 3 3 3 <none> 2m42s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-grafana 1/1 1 1 2m42s
deployment.apps/prometheus-kube-state-metrics 1/1 1 1 2m42s
deployment.apps/prometheus-prometheus-oper-operator 1/1 1 1 2m42s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-grafana-58d5bbf9f4 1 1 1 2m42s
replicaset.apps/prometheus-kube-state-metrics-556f95ff74 1 1 1 2m42s
replicaset.apps/prometheus-prometheus-oper-operator-78595b64c 1 1 1 2m42s
NAME READY AGE
statefulset.apps/alertmanager-prometheus-prometheus-oper-alertmanager 1/1 2m37s
statefulset.apps/prometheus-prometheus-prometheus-oper-prometheus 1/1 2m26s
[root@kubemaster stable]#위와 같이 모든 Pod가 정상 배포되어 Running 상태이며, Service, Deployment, DaemonSet, ReplicatSet, StatefulSet 등이 모두 정상 구성되어 있습니다.
특히 Pod가 Node Label에 맞게 배치되었는지 여부를 확인해야 합니다.
[root@kubemaster stable]# kubectl get pod -n monitoring -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 4m27s 10.233.124.37 kubeworker1 <none> <none>
prometheus-grafana-58d5bbf9f4-dkqxm 3/3 Running 0 4m32s 10.233.124.36 kubeworker1 <none> <none>
prometheus-kube-state-metrics-556f95ff74-ghb92 1/1 Running 0 4m32s 10.233.124.35 kubeworker1 <none> <none>
prometheus-prometheus-node-exporter-2tkzw 1/1 Running 0 4m32s 192.168.56.102 kubemaster <none> <none>
prometheus-prometheus-node-exporter-qmnhh 1/1 Running 0 4m32s 192.168.56.101 kubeworker2 <none> <none>
prometheus-prometheus-node-exporter-s4cbk 1/1 Running 0 4m32s 192.168.56.103 kubeworker1 <none> <none>
prometheus-prometheus-oper-operator-78595b64c-8fqxl 2/2 Running 0 4m32s 10.233.124.34 kubeworker1 <none> <none>
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 4m16s 10.233.124.39 kubeworker1 <none> <none>
[root@kubemaster stable]# 위와 같이 배치된 노드가 kubeworker1 즉 key=monitoring이 등록된 서버임을 확인할 수 있으며, node-exporter의 경우 daemonset으로 모든 노드에 배포되어 있습니다.
3) Dashboard 활용
다음으로 Prometheus와 Grafana의 Dashboard 활용 방법에 대해 살펴보겠습니다.
현재 Prometheus와 Grafana는 위에서 확인한 바와 같이 Service를 모두 ClusterIP로 구성되어 있습니다.
이를 직접 바로 접근 가능하도록 NodePort로 변경하여 구성해 보도록 하겠습니다.
kubectl edit 명령어를 활용하여 Grafana는 NodePort 30001, Prometheus는 NodePort 30002로 구성합니다.
[Grafana yaml]
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-03-03T12:32:44Z"
labels:
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Tiller
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 6.6.2
helm.sh/chart: grafana-5.0.4
name: prometheus-grafana
namespace: monitoring
resourceVersion: "40379"
selfLink: /api/v1/namespaces/monitoring/services/prometheus-grafana
uid: 6abbf5f4-e965-4efa-867c-6927b06cc1d4
spec:
clusterIP: 10.233.23.0
ports:
- name: service
nodePort: 30001
port: 80
protocol: TCP
targetPort: 3000
selector:
app.kubernetes.io/instance: prometheus
app.kubernetes.io/name: grafana
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}[Prometheus yaml]
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-03-03T12:32:45Z"
labels:
app: prometheus-operator-prometheus
chart: prometheus-operator-8.10.0
heritage: Tiller
release: prometheus
self-monitor: "true"
name: prometheus-prometheus-oper-prometheus
namespace: monitoring
resourceVersion: "40388"
selfLink: /api/v1/namespaces/monitoring/services/prometheus-prometheus-oper-prometheus
uid: b91772e9-11f9-4db1-8939-2300ee5ef5c7
spec:
clusterIP: 10.233.8.84
ports:
- name: web
nodePort: 30002
port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
prometheus: prometheus-prometheus-oper-prometheus
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}위와 같이 service를 편집한 후 Service를 재확인해 보도록 하겠습니다.
[root@kubemaster stable]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 15m
prometheus-grafana NodePort 10.233.23.0 <none> 80:30001/TCP 15m
prometheus-kube-state-metrics ClusterIP 10.233.4.171 <none> 8080/TCP 15m
prometheus-operated ClusterIP None <none> 9090/TCP 14m
prometheus-prometheus-node-exporter ClusterIP 10.233.54.30 <none> 9100/TCP 15m
prometheus-prometheus-oper-alertmanager ClusterIP 10.233.29.188 <none> 9093/TCP 15m
prometheus-prometheus-oper-operator ClusterIP 10.233.9.20 <none> 8080/TCP,443/TCP 15m
prometheus-prometheus-oper-prometheus NodePort 10.233.8.84 <none> 9090:30002/TCP 15m
[root@kubemaster stable]#위와 같이 NodePort로 변경된 것을 확인할 수 있습니다.
이제 이를 기반으로 Dashboard에 접근해 보겠습니다.
먼저 Grafana 입니다.
Default ID : admin
Default PW : prom-operator
접근은 NodePort로 구성하여 Kubernetes의 클러스터에 포함되어 있는 모든 노드에서 접근이 가능하며, 30001포트입니다.

로그인 ID/PW를 입력하면 다음과 같은 메인 화면에 접속할 수 있습니다.

이중 기본으로 구성되어 있는 다양한 메인 화면 필터를 이용하여 몇몇 주요 모니터링 요소를 살펴보겠습니다.
상단의 Home이라고 표기되어 있는 콤보박스를 클릭하면 아래와 같은 다양한 필터 화면을 볼 수 있습니다.

이중 Compute Resources/Cluster, Compute Resources/Namespace(Pod), Compute Resource/Node(Pods), Compute Resources/Pod 등의 리소스를 확인할 수 있습니다.




이와 같은 기본으로 제공되는 정보이외에도
왼쪽의 + Create를 활용하여 원하는 대시보드를 커스터 마이징할 수 있으며, 데이터베이스를 추가하여 정보를 필터링할 수도 있습니다. 이로 인해 Grafana는 Prometheus 뿐만 아니라 다양한 저장소와 연결되어 데이터를 표출할 수 있습니다.
다음으로 Prometheus Dashboard입니다.
마찬가지로 NodePort로 기동되어 있어 모든 Kubernetes Cluster Node에서 접근이 가능하며, 30002 포트로 접근합니다.
최초 로그인 시 아래 화면에 접근할 수 있습니다.

Prometheus가 수집한 데이터의 Raw 데이터와 이를 기반으로 Graph로 표출한 내용을 살펴볼 수 있습니다. Query에 사용가능한 다양한 Expression을 사용할 수 있으며, 이 중 하나를 조회해 보겠습니다.
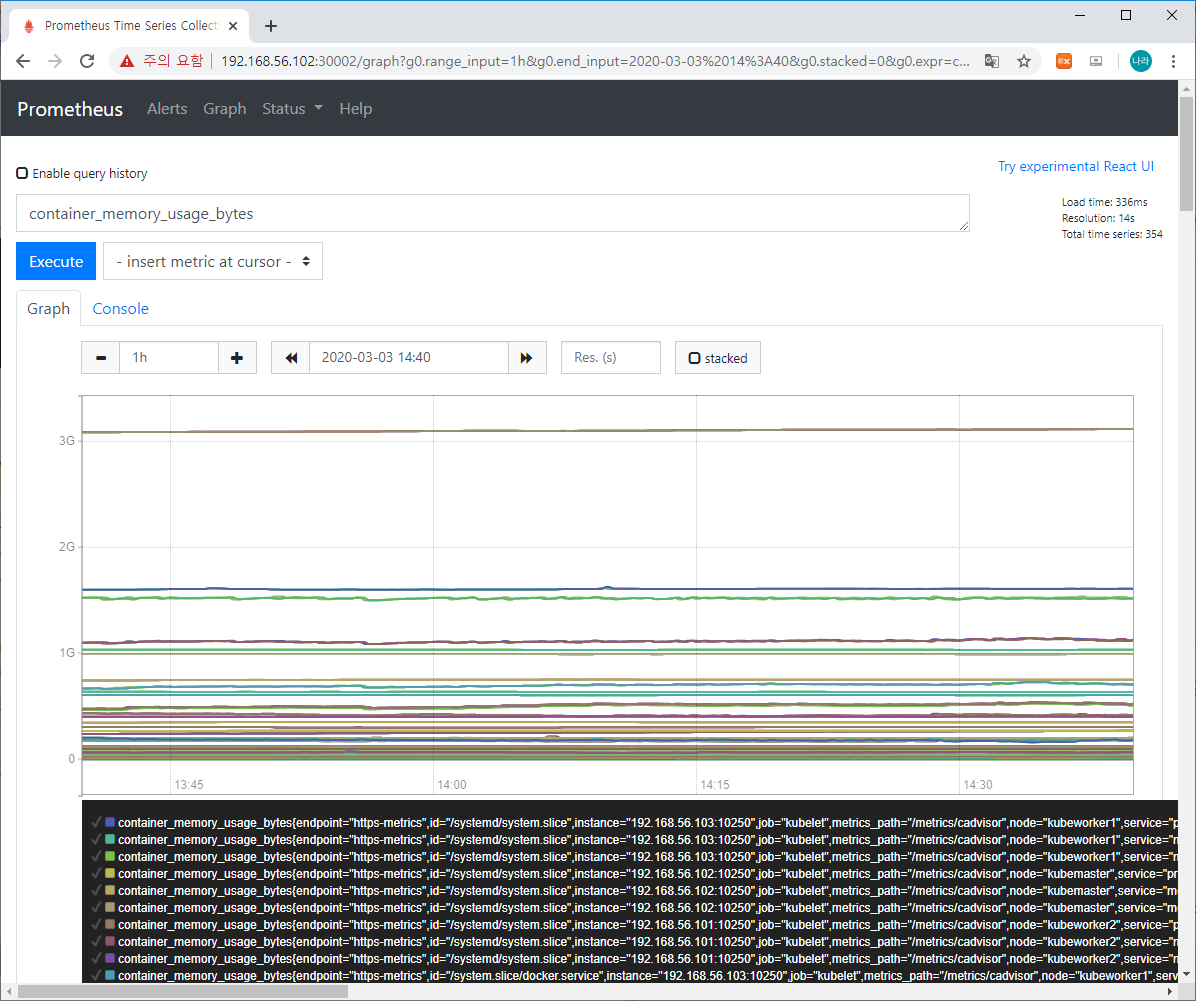
위는 container_memory_usage_bytes에 대한 Query 결과를 그래프로 조회한 화면입니다.
그 밖에 targets에서는 다양한 monitoring 대상 특히 node-exporter가 배치된 노드 정보가 표출되며, Alerts에서는 알람 기능에 대해 표출합니다.
사실 그래픽 적으로 뛰어난 표출 방식이 아니다 보니 Grafana를 활용하여 운영환경에 적합하게 커스터마이징하는것이 효율성을 높일 수 있습니다.
결론
지금까지 Kubernetes Package Manager인 Helm을 활용하여 Prometheus와 Grafana를 배포해 보았습니다. Prometheus와 Grafana는 사실 이정도 수준으로 살펴볼 수 있는 Echo System이 아닌 보다 복잡하면서도 다양한 기능을 제공하고 있습니다. 나중에 시간이 되면 자세하게 포스팅해보는 시간을 갖어 보도록 하겠습니다.
다만 이정도의 기능만으로도 충분히 분산트랜잭션에 대한 모니터링 및 관리가 가능하다는 점을 미루어 컨테이너 환경 특히 MSA 환경을 적용하는 많은 IT 구독자 분들께서는 한번쯤 설치해보고 운영해 보는 것이 어떨지 싶네요.
'③ 클라우드 > ⓚ Kubernetes' 카테고리의 다른 글
| K8S 보안 "인증/인가" (0) | 2020.06.13 |
|---|---|
| 기동 실패 된 Kubernetes Pod 또는 Docker Container에 접근하기 (0) | 2020.03.12 |
| minikube 5분안에 설치하기 (0) | 2020.03.03 |
| Ansible을 활용한 kubernetes 운영환경 구축하기 (0) | 2020.02.28 |
| Kubernetes 특정 node에 pod 배포하기 - label, nodeSelector, affinity(nodeAffinity, podAffinity) (0) | 2020.01.12 |
- Total
- Today
- Yesterday
- webtob
- JBoss
- OpenStack
- apache
- kubernetes
- JEUS6
- Da
- TA
- Architecture
- SWA
- Docker
- wildfly
- node.js
- k8s
- git
- aa
- openstack tenant
- jeus
- JEUS7
- nodejs
- 마이크로서비스
- aws
- MSA
- 쿠버네티스
- 아키텍처
- SA
- API Gateway
- 마이크로서비스 아키텍처
- 오픈스택
- openstack token issue
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |