
티스토리 뷰
개요
MSA 환경에서 Telemetry의 중요성은 이미 수많은 포스팅과 수많은 포스터들로 부터 강조되어 왔으며, 이미 많은 자료들을 통해 활용 방안들이 다뤄지고 있다. Telemetry는 로깅, 모니터링, 추적 기능을 포괄하여 분산 트랜잭션 환경에서 효과적인 유지보수를 수행할 수 있도록 지원하는 도구이자, 무엇보다 자동화된 수집체계를 구성하는 것이 중요하다.
이번 포스팅에서는 msa 환경에서 가장 많이 활용되는 로깅 컴포넌트로 ElasticSearch 기반의 EFK를 다뤄보도록 하자. 포스팅에서는 EFK 구성 설계, EFK 구축, EFK 활용으로 나누어 작성하고자 한다.
EFK 구성 설계
ElasticSearch는 실시간 검색/분석 기능을 제공하고, 분산환경에 저장되어 있는 로그를 통합으로 수집함으로써 통합 저장소의 역할을 수행할 수 있다. 또한, 데이터의 사용빈도, 중요도에 따라 로그의 라이프사이클을 관리하여 효과적인 디스크 관리를 지원한다.
EFK는 ElasticSeach + FluentD + Kibana의 조합을 의미한다.
- ElasticSearch : 저장을 위한 모듈로 수집한 데이터가 라이프사이클에 의해 저장되는 공간
- FluentD : 수집 및 정제를 위한 모듈로 Kubernetes 환경에 DaemonSet으로 구성
- Kibana : 분석을 위한 모듈로 ElasticSearch에 저장된 데이터를 Visualize하는 대시보드
수집
수집모듈은 FluentD를 대신하여 Kafka + Logstash를 구성할 수 있으며, 이렇게 구성되는 환경을 ELK Stack이라고 한다. 물론 FluentD + Logstash로 구성하여 수집과 정제를 구분하여 설계할 수도 있다. 수집이 가능한 포맷으로는 로그파일, 데이터베이스, Streaming 또는 수집 API를 제공하여 데이터를 수집할 수 있다.
정제
정제 모듈은 수집 대상으로 부터 수집한 데이터의 변환과 필터링을 통해 Visualize 하기 위한 기틀을 잡는 역할이다. Logstash를 추가하여 구성할 경우 수집 모듈은 Logstash로 로그를 전송하는 역할만 담당하게 되지만, FluentD와 같이 필터링 작업은 사전에 진행할 경우 변환이 완료된 형태의 데이터를 수집 대상 노드에서 전송하게 된다.
저장
저장 모듈은 ElasticSearch를 의미한다. EFK, ELK 모두 ElasticSearch가 핵심이며, 이 저장소를 기반으로 동작한다고 볼 수 있다. ElasticSearch는 역색인구조로 저장되는 NoSQL DB로 데이터의 라이프사이클을 관리하고 백업/복구를 관리하는 저장소이다. Elasticsearch 클러스터는 하나 이상의 노드들로 이루어지며, 대표적인 노드는 마스터 노드와 데이터 노드가 있다.
마스터 노드는 인덱스의 메타 데이터(생성, 삭제), 샤드의 위치와 같은 클러스터 상태(Cluster Status) 정보, 데이터 저장을 관리하는 역할을 수행한다. 클러스터마다 하나의 마스터 노드가 존재하며 마스터 노드의 역할을 수행할 수 있는 노드가 없다면 클러스터는 작동이 중지된다. (후보 선출 방식으로 장애 발생시 즉시 대체가 가능하다.)
클러스터가 커져서 노드와 샤드들의 개수가 많아지게 되면 모든 노드들이 마스터 노드의 정보를 계속 공유하는 것은 부담이 될 수 있다. 이때는 마스터 노드의 역할을 수행 할 후보 노드들만 따로 설정해서 유지하는 것이 전체 클러스터 성능에 도움이 될 수 있다. 마스터 노드로 사용하지 않는 노드들은 설정값을 node.master: false 로 하여 마스터 노드의 역할을 하지 않도록 구성한다.
데이터 노드는 실제로 색인된 데이터를 저장하고 있는 노드이다. 클러스터에서 마스터 노드와 데이터 노드를 분리하여 설정 할 때 마스터 후보 노드들은 node.data: false 로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 할 수 있다. 이렇게 하면 마스터 노드는 데이터는 저장하지 않고 클러스터 관리만 하게 되고, 데이터 노드는 클러스터 관리 작업으로부터 자유롭게 되어 데이터 처리에만 집중할 수 있다.
그 밖에 데이터 변환을 위한 Ingest 노드, 다중 클러스터를 관리하는 Tribe 노드, 복잡한 조회 및 집계를 포함할 경우 사용하는 Coordinating Only 노드(Client 노드) 등이 있다.
분석
분석 모듈은 Kibana를 통해 저장된 데이터를 분석하여 시각화하는 도구이다. 수집데이터에 대한 통합검색, 실시간 모니터링을 지원하며, 장애관리, 이상감지, 자동알림을 통해 유지보수 효율성을 제고해 주는 모듈이다.
이와 같이 주요 모듈을 기반으로 설계하고자 할때 아래와 같은 아키텍처로 마이크로서비스 환경에 구축해 볼 수 있을 것이다.


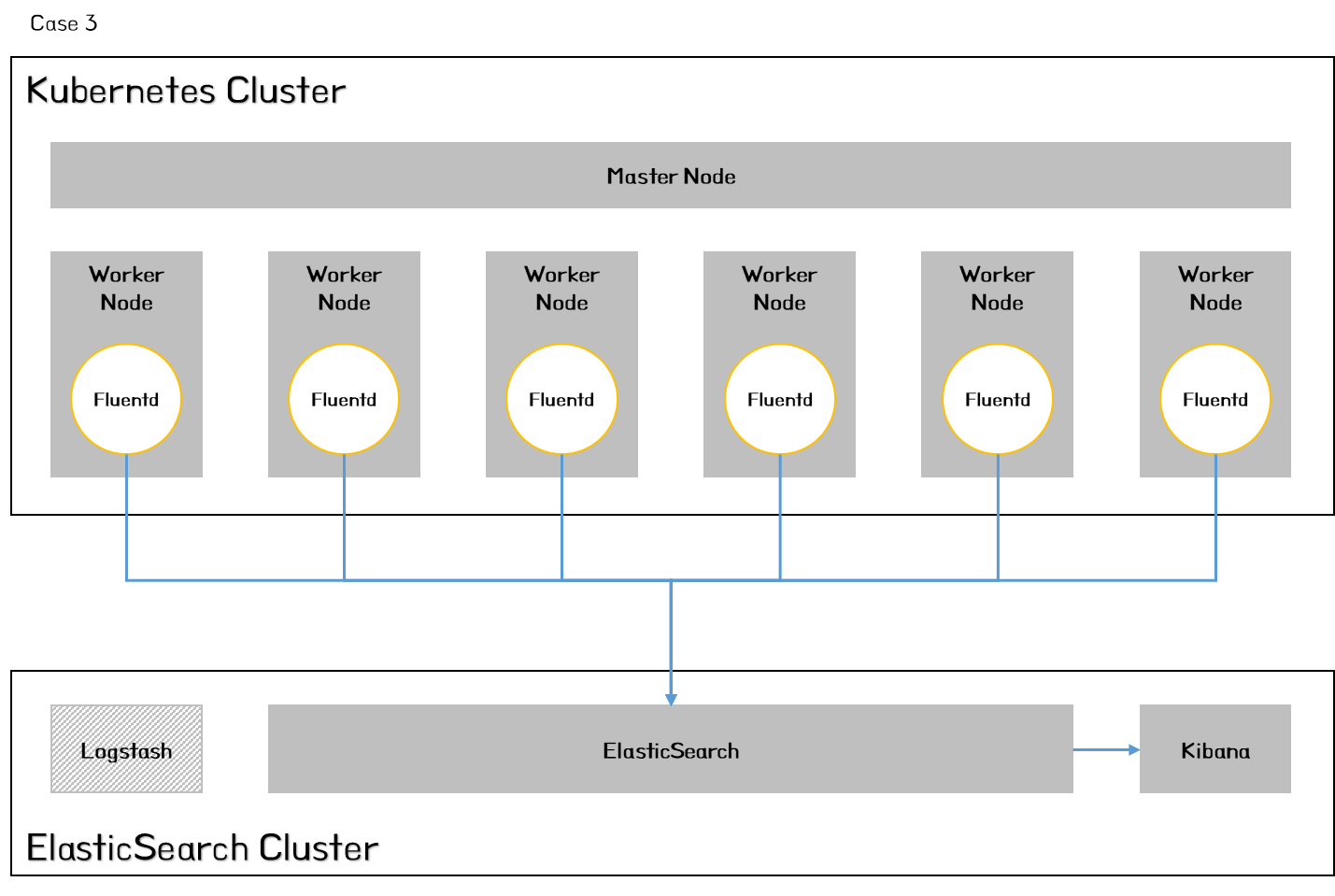
위와 같이 세가지 아키텍처를 고려해 볼 수 있을 것이다.
- Case 1 : 수집은 Fluentd, 수집 안정성을 위해 Kafka, 정제는 Logstash, 저장은 ElasticSearch, 분석은 Kibana로 구성
- Case 2 : 수집은 Fluentd, 정제는 Logstash, 저장은 ElasticSearch, 분석은 Kibana로 구성
- Case 3 : 수집 및 정제는 Fluentd, 저장은 ElasticSearch, 분석은 Kibana로 구성
지금부터는 Case 3을 기준으로하여 EFK를 직접 구축해 보도록 하자.
ElasticSearch 구축
- namespace 생성
- elasticsearch 마스터 노드 생성
- elasticsearch 데이터 노드 생성
- elasticsearch 클라이언트 노드 생성
a. namespace 생성
> namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kube-logging> 반영
apiVersion: v1
kind: Namespace
metadata:
name: kube-logging> 확인
[root@ip-192-168-78-195 efk]# kubectl get namespaces
NAME STATUS AGE
default Active 3d
kube-logging Active 2m56s
kube-node-lease Active 3d
kube-public Active 3d
kube-system Active 3d
[root@ip-192-168-78-195 efk]#b. elasticsearch 마스터 노드 생성
> elasticsearch-master-configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-logging
name: elasticsearch-master-config
labels:
app: elasticsearch
role: master
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: true
data: false
ingest: false
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
---> elasticsearch-master-service.yaml
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-logging
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
ports:
- port: 9300
name: transport
selector:
app: elasticsearch
role: master
---> elasticsearch-master-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: kube-logging
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
role: master
template:
metadata:
labels:
app: elasticsearch
role: master
spec:
containers:
- name: elasticsearch-master
image: docker.elastic.co/elasticsearch/elasticsearch:7.3.0
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-master
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: storage
mountPath: /data
volumes:
- name: config
configMap:
name: elasticsearch-master-config
- name: "storage"
emptyDir:
medium: ""
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
---> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f elasticsearch-master-configmap.yaml -f elasticsearch-master-service.yaml -f elasticsearch-master-deployment.yaml
configmap/elasticsearch-master-config created
service/elasticsearch-master created
deployment.apps/elasticsearch-master created
[root@ip-192-168-78-195 efk]#> 확인
[root@ip-192-168-78-195 efk]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-master-745c995d88-4vb2s 1/1 Running 0 45s
[root@ip-192-168-78-195 efk]#c. elasticsearch 데이터 노드 생성
> elasticsearch-data-configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-logging
name: elasticsearch-data-config
labels:
app: elasticsearch
role: data
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: false
data: true
ingest: false
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
---> elasticsearch-data-service.yaml
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-logging
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
ports:
- port: 9300
name: transport
selector:
app: elasticsearch
role: data
---> elasticsearch-data-statefulset.yaml
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: kube-logging
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
serviceName: "elasticsearch-data"
selector:
matchLabels:
app: elasticsearch-data
role: data
replicas: 1
template:
metadata:
labels:
app: elasticsearch-data
role: data
spec:
containers:
- name: elasticsearch-data
image: docker.elastic.co/elasticsearch/elasticsearch:7.3.0
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-data
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms300m -Xmx300m"
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: elasticsearch-data-persistent-storage
mountPath: /data/db
volumes:
- name: config
configMap:
name: elasticsearch-data-config
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: elasticsearch-data-persistent-storage
annotations:
volume.beta.kubernetes.io/storage-class: "gp2"
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: standard
resources:
requests:
storage: 10Gi
---> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f elasticsearch-data-configmap.yaml -f elasticsearch-data-service.yaml -f elasticsearch-data-statefulset.yaml
configmap/elasticsearch-data-config created
service/elasticsearch-data created
statefulset.apps/elasticsearch-data created
[root@ip-192-168-78-195 efk]#> 확인
[root@ip-192-168-78-195 efk]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-data-0 1/1 Running 0 35s
elasticsearch-master-745c995d88-4vb2s 1/1 Running 0 4m40s
[root@ip-192-168-78-195 efk]#d. elasticsearch 클라이언트 노드 생성
> elasticsearch-client-configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-logging
name: elasticsearch-client-config
labels:
app: elasticsearch
role: client
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: false
data: false
ingest: true
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
---> elasticsearch-client-service.yaml
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-logging
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
ports:
- port: 9200
name: client
- port: 9300
name: transport
selector:
app: elasticsearch
role: client
---> elasticsearch-client-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: kube-logging
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
role: client
template:
metadata:
labels:
app: elasticsearch
role: client
spec:
containers:
- name: elasticsearch-client
image: docker.elastic.co/elasticsearch/elasticsearch:7.3.0
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-client
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9200
name: client
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: storage
mountPath: /data
volumes:
- name: config
configMap:
name: elasticsearch-client-config
- name: "storage"
emptyDir:
medium: ""
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
---> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f elasticsearch-client-configmap.yaml -f elasticsearch-client-service.yaml -f elasticsearch-client-deployment.yaml
configmap/elasticsearch-client-config created
service/elasticsearch-client created
deployment.apps/elasticsearch-client created
[root@ip-192-168-78-195 efk]#> 확인
[root@ip-192-168-78-195 efk]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-578dd48f84-kx2rf 1/1 Running 0 22s
elasticsearch-data-0 1/1 Running 0 3m23s
elasticsearch-master-745c995d88-4vb2s 1/1 Running 0 7m28s
[root@ip-192-168-78-195 efk]#e. 구축 상태 확인
위와 같이 각 노드 설치가 완료되면, master node에 아래와 같은 문구가 출력되는지 확인한다.
[root@ip-192-168-78-195 efk]# kubectl logs -f -n kube-logging $(kubectl get pods -n kube-logging | grep elasticsearch-master | sed -n 1p | awk '{print $1}') | grep "Cluster health status changed from \[YELLOW\] to \[GREEN\]"
{"type": "server", "timestamp": "2022-02-06T07:25:06,260+0000", "level": "INFO", "component": "o.e.c.r.a.AllocationService", "cluster.name": "elasticsearch", "node.name": "elasticsearch-master", "cluster.uuid": "FqOtUobfRF-g46URNGZKfA", "node.id": "jglC7I-tRaqCXt7ru_uZKQ", "message": "Cluster health status changed from [YELLOW] to [GREEN] (reason: [shards started [[.monitoring-es-7-2022.02.06][0]] ...])." }f. X-Pack 적용
X-Pack은 보안, 알림, 모니터링, 보고, 그래프 기능을 설치하기 편리한 단일 패키지로 번들 구성한 Elastic Stack 확장 프로그램이다. X-Pack 구성 요소는 서로 원활하게 연동할 수 있도록 설계되었지만 사용할 기능을 손쉽게 활성화하거나 비활성화할 수 있다.
클러스터 보안을 위해 X-Pack 보안 모듈을 활성화했고(각 노드 별 configmap 확인), 암호를 초기화 해보도록 하자.
[root@ip-192-168-78-195 efk]# kubectl exec -it $(kubectl get pods -n kube-logging | grep elasticsearch-client | sed -n 1p | awk '{print $1}') -n kube-logging -- bin/elasticsearch-setup-passwords auto -b
Changed password for user apm_system
PASSWORD apm_system = xxxxxxxxxxxxxxxxx
Changed password for user kibana
PASSWORD kibana = xxxxxxxxxxxxxxxxx
Changed password for user logstash_system
PASSWORD logstash_system = xxxxxxxxxxxxxxxxx
Changed password for user beats_system
PASSWORD beats_system = xxxxxxxxxxxxxxxxx
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = xxxxxxxxxxxxxxxxx
Changed password for user elastic
PASSWORD elastic = aaaaaaaaaaaaaaa
[root@ip-192-168-78-195 efk]#마지막 user elastic password를 기록해 두고, kubernetes secret을 추가한다.
[root@ip-192-168-78-195 efk]# kubectl create secret generic elasticsearch-pw-elastic -n kube-logging --from-literal password=aaaaaaaaaaaaaaaa
secret/elasticsearch-pw-elastic created
[root@ip-192-168-78-195 efk]#Kibana 구축
- kibana 생성
- 대시보드 접속
a. kibana 생성
> kibana-configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-logging
name: kibana-config
labels:
app: kibana
data:
kibana.yml: |-
server.host: 0.0.0.0
elasticsearch:
hosts: ${ELASTICSEARCH_HOSTS}
username: ${ELASTICSEARCH_USER}
password: ${ELASTICSEARCH_PASSWORD}
---> kibana-service.yaml
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-logging
name: kibana
labels:
app: kibana
spec:
type: LoadBalancer
ports:
- port: 80
name: webinterface
targetPort: 5601
selector:
app: kibana
---> kibana-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: kube-logging
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.3.0
ports:
- containerPort: 5601
name: webinterface
env:
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch-client.kube-logging.svc.cluster.local:9200"
- name: ELASTICSEARCH_USER
value: "elastic"
- name: ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: elasticsearch-pw-elastic
key: password
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
volumes:
- name: config
configMap:
name: kibana-config
---> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f kibana-configmap.yaml -f kibana-service.yaml -f kibana-deployment.yaml
configmap/kibana-config created
service/kibana created
deployment.apps/kibana created
[root@ip-192-168-78-195 efk]#> 확인
[root@ip-192-168-78-195 efk]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-578dd48f84-kx2rf 1/1 Running 0 28m
elasticsearch-data-0 1/1 Running 0 31m
elasticsearch-master-745c995d88-4vb2s 1/1 Running 0 35m
kibana-5cb685c5f4-x66xv 1/1 Running 0 3m31s
[root@ip-192-168-78-195 efk]# kubectl get service -n kube-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-client ClusterIP 10.100.4.148 <none> 9200/TCP,9300/TCP 29m
elasticsearch-data ClusterIP 10.100.216.144 <none> 9300/TCP 32m
elasticsearch-master ClusterIP 10.100.1.255 <none> 9300/TCP 36m
kibana LoadBalancer 10.100.142.131 aaaaaa259dae34aa1acab098bd9cbeab-590462194.ap-northeast-2.elb.amazonaws.com 80:32111/TCP 3m51s
[root@ip-192-168-78-195 efk]#b. 대시보드 접속
id는 elastic, password는 앞서 초기화 한 암호(aaaaaaaaa)를 입력하면 된다. 현재 시점에는 Fluentd가 설치되어 있지 않아 수집이 진행되고 있는 상태는 아니며, 기본 환경에 대해 확인 후 Fluentd 설치를 진행해 보도록 하자.
> Management
왼쪽 하단의 톱니바퀴(Management) 메뉴를 선택한다. 먼저 살펴볼 내용은 Management > Security > Users이다.
User 정보를 수정하거나, Create User를 통해 신규 유저를 할당할 수 있다. 특히 사전에 정의되어 있는 27개의 Role을 기반으로 사용자를 추가할 수 있다.
User Role : https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-roles.html
index management의 경우 Fluentd 설치 이후 살펴보도록 하고, Management 바로 위 메뉴인 Monitoring을 살펴보자.
> Monitoring
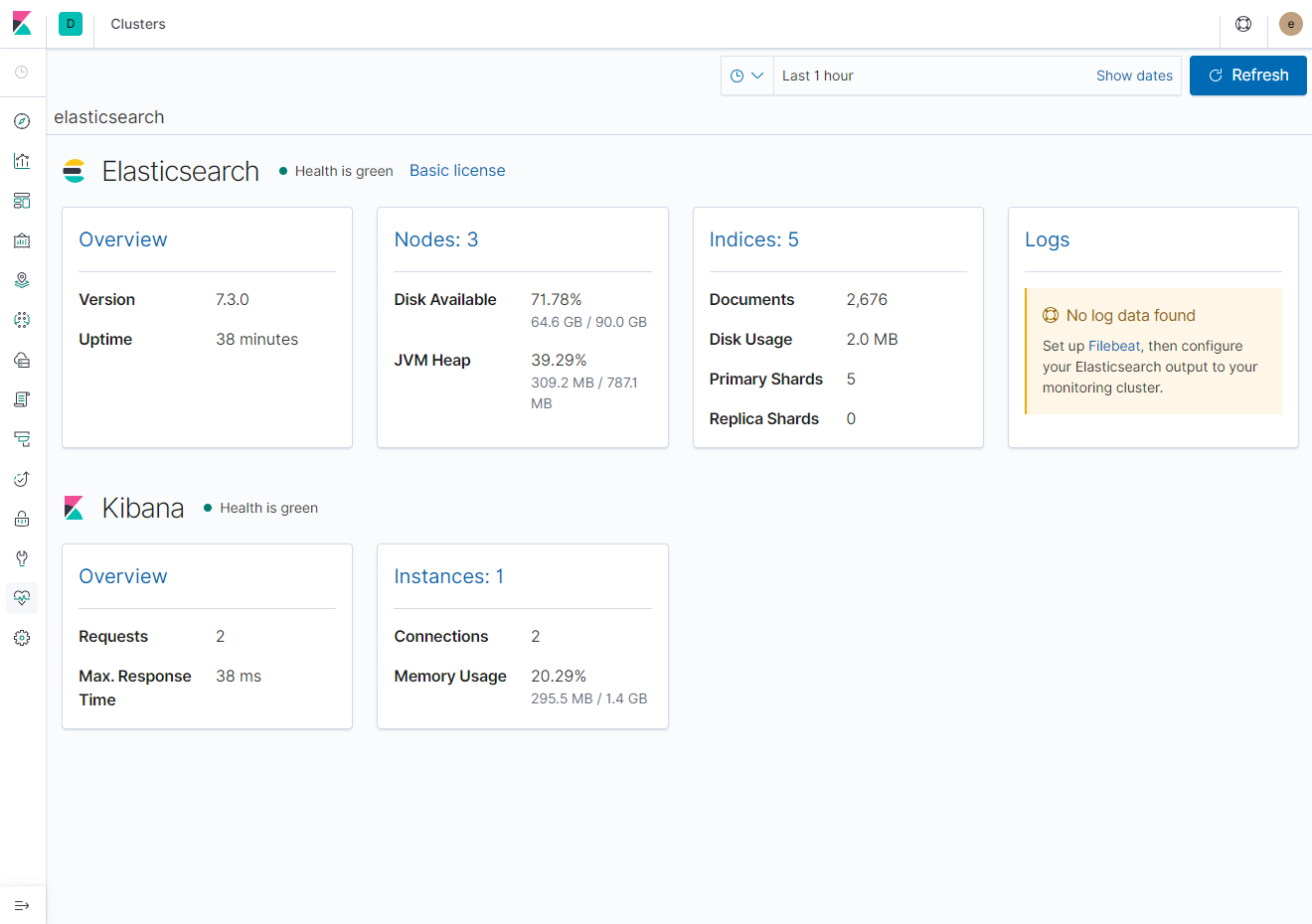
모니터링 화면에서는 ElasticSearch와 Kibana 관련 정보를 확인할 수 있다. 먼저 ElasticSearch에서는 Resource 정보와 Node, Indice, Log 정보를 다음과 같이 각각 확인 가능하다.
- Overview (리소스 정보)
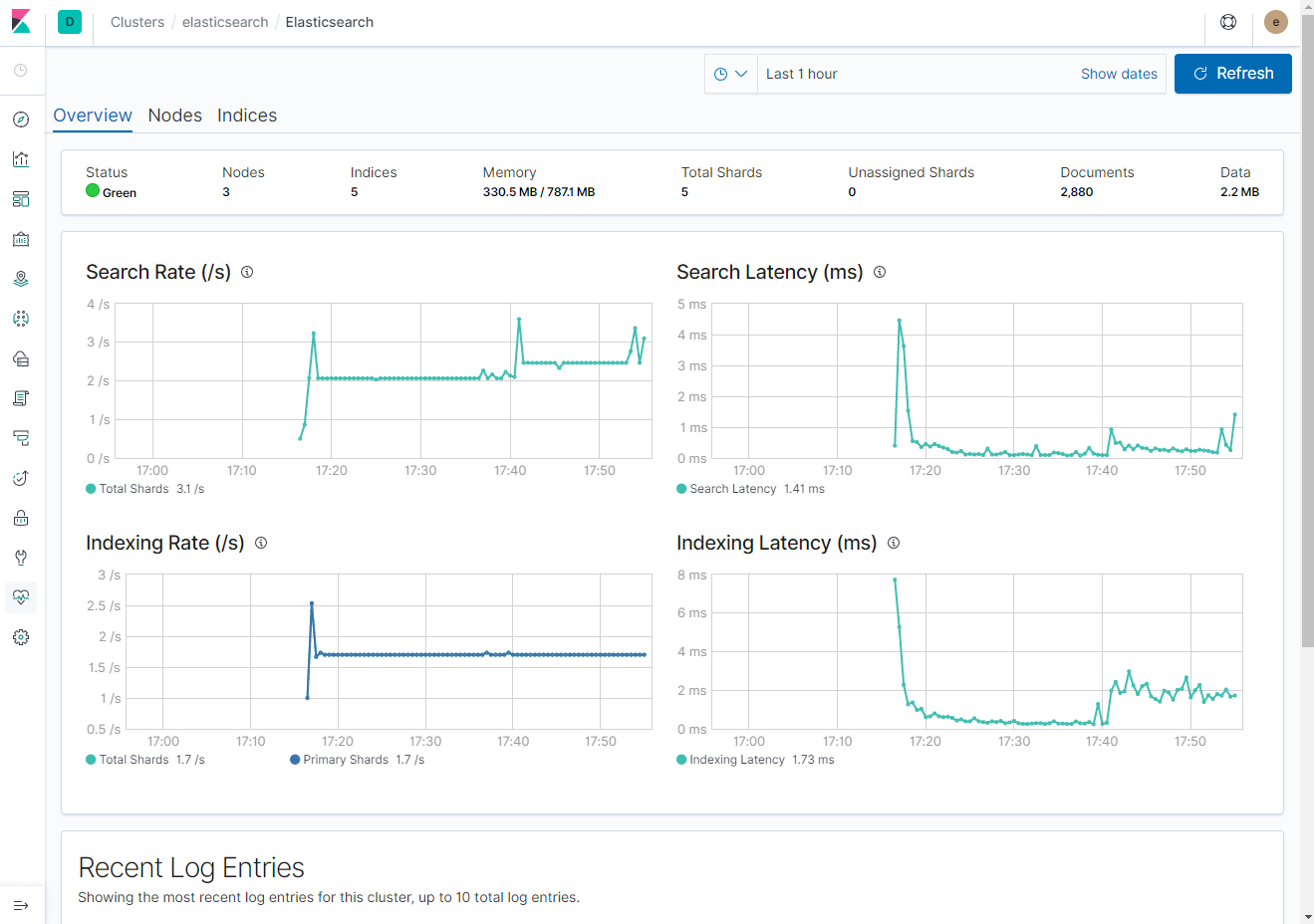
- Nodes (노드 정보)
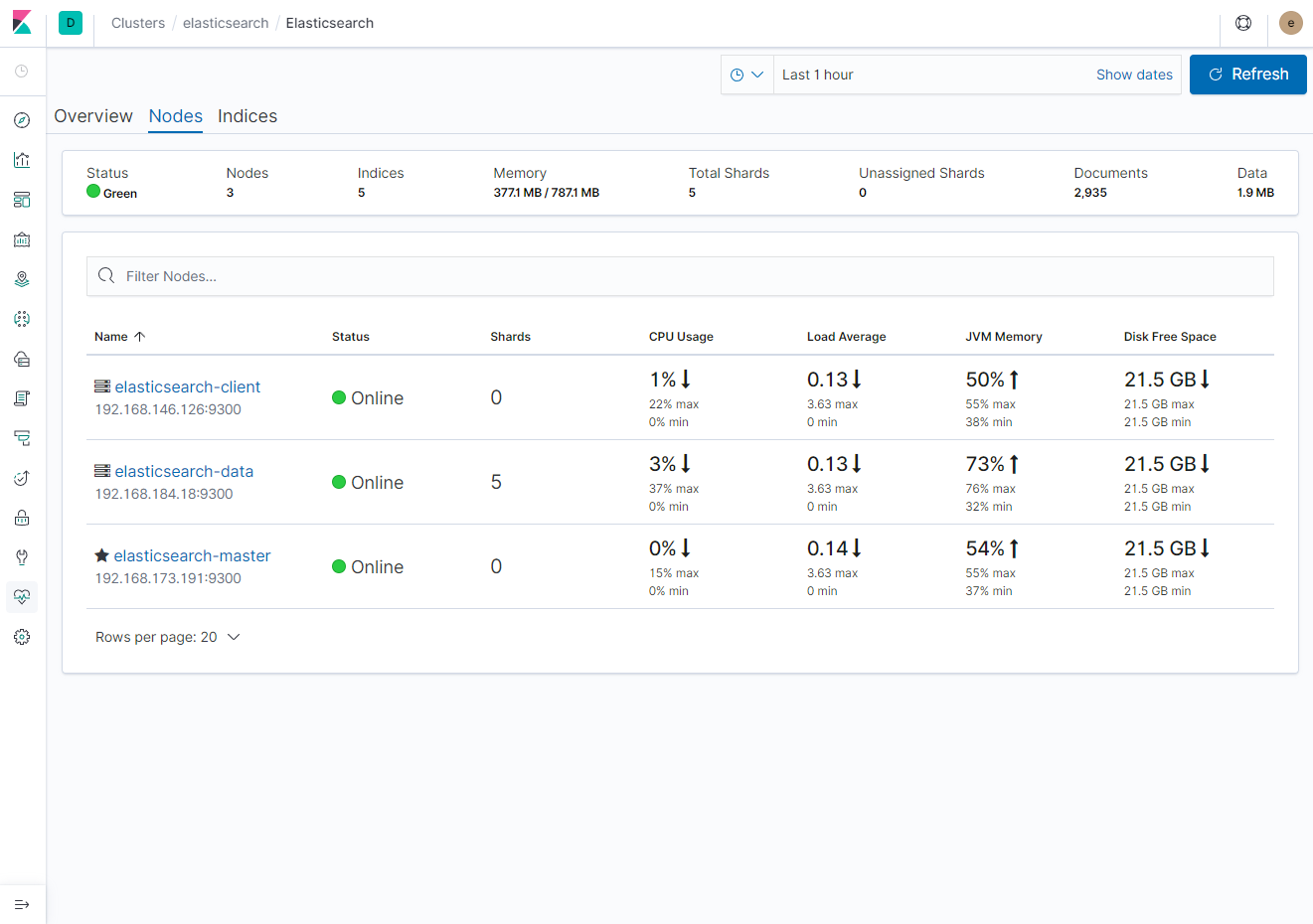
Nodes 정보에서는 ElasticSearch 노드에 대해 확인할 수 있다. 이 중 앞에 별표가 붙어 있는 노드가 Master 노드이다.
- Indices (통계 지표)
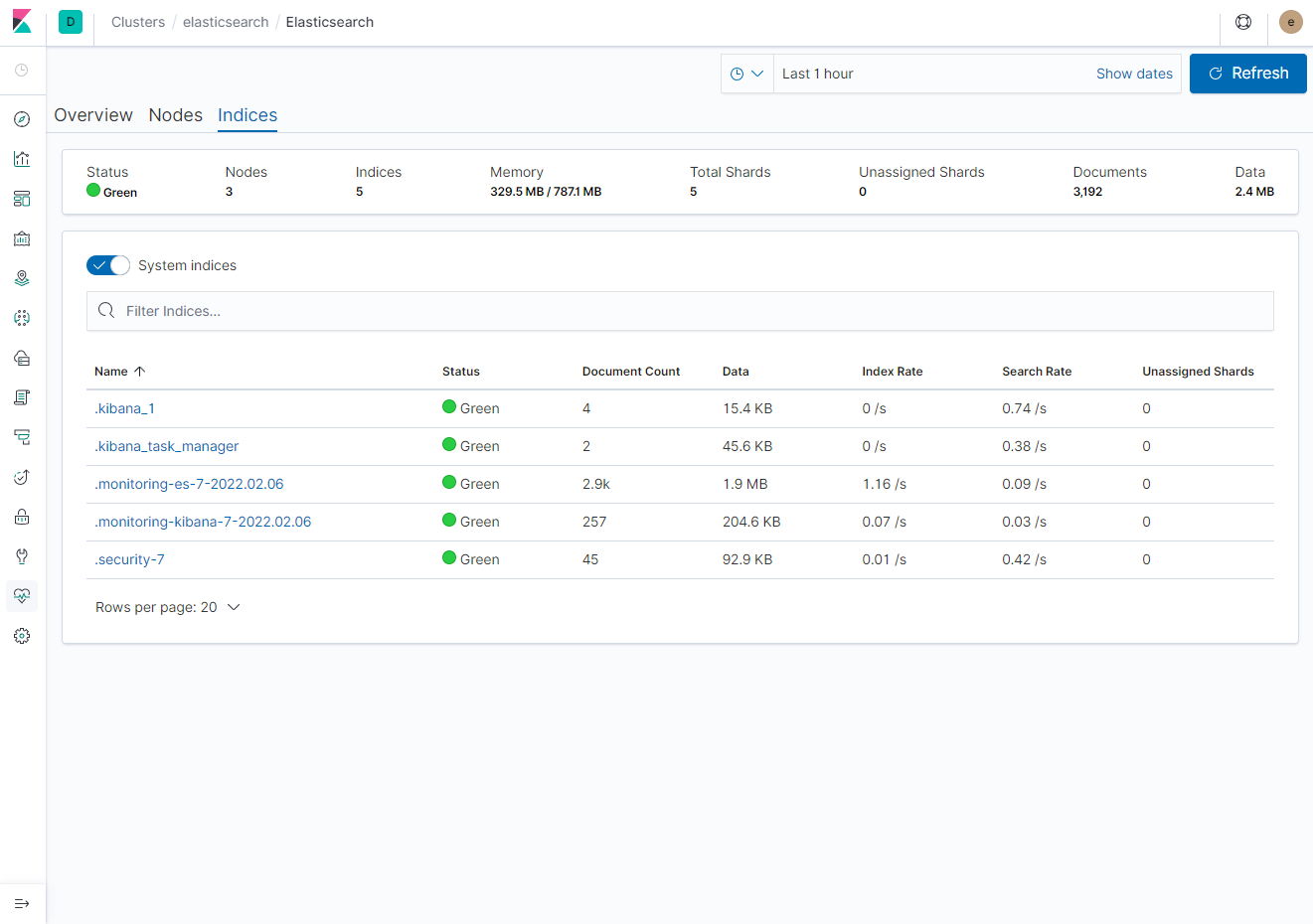
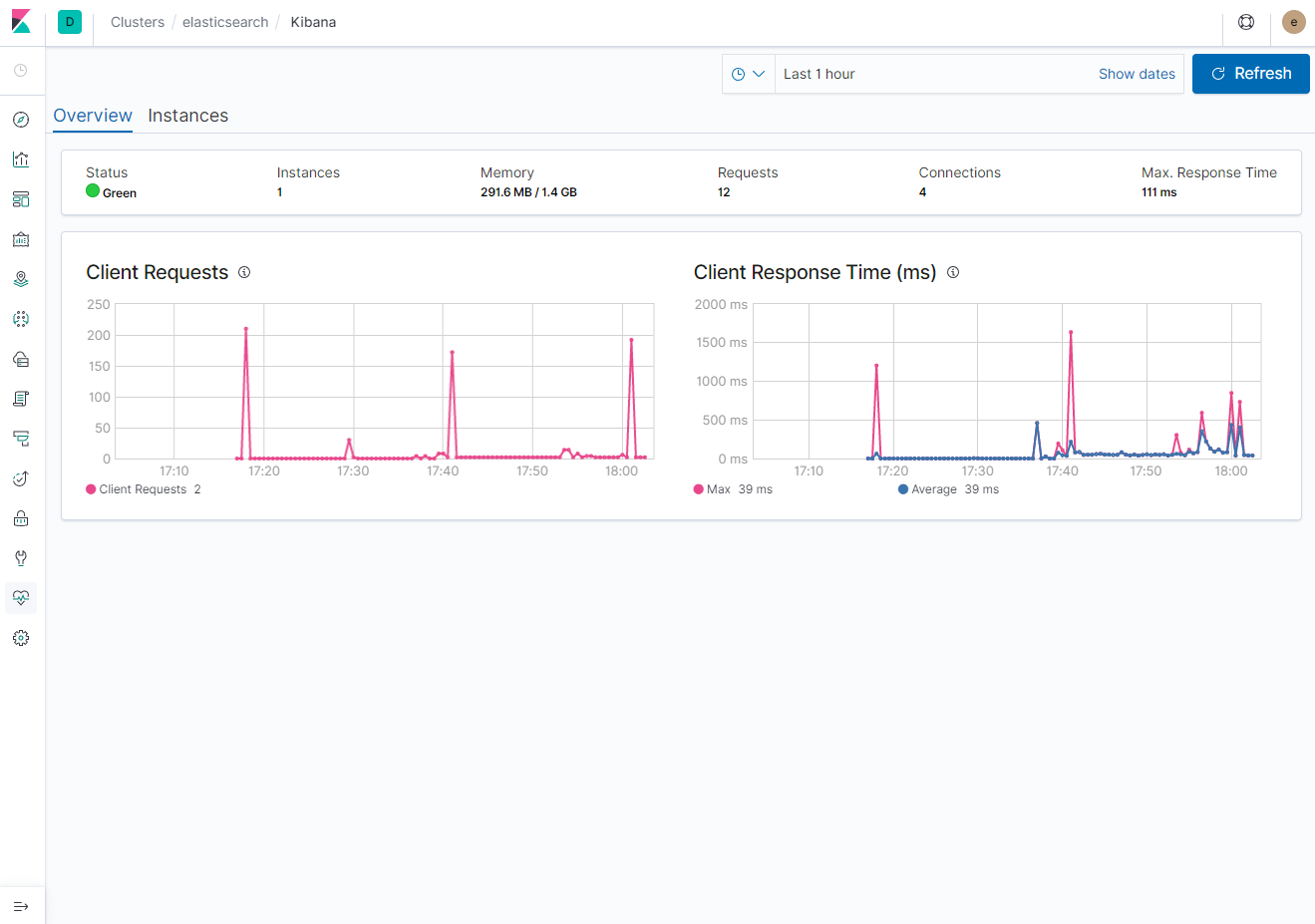
Log 정보는 Fluentd 설치 이후 살펴보도록 하자. Kibana 항목에서는 Client Request, Response Time, Instance 정보를 확인할 수 있다.
- Overview
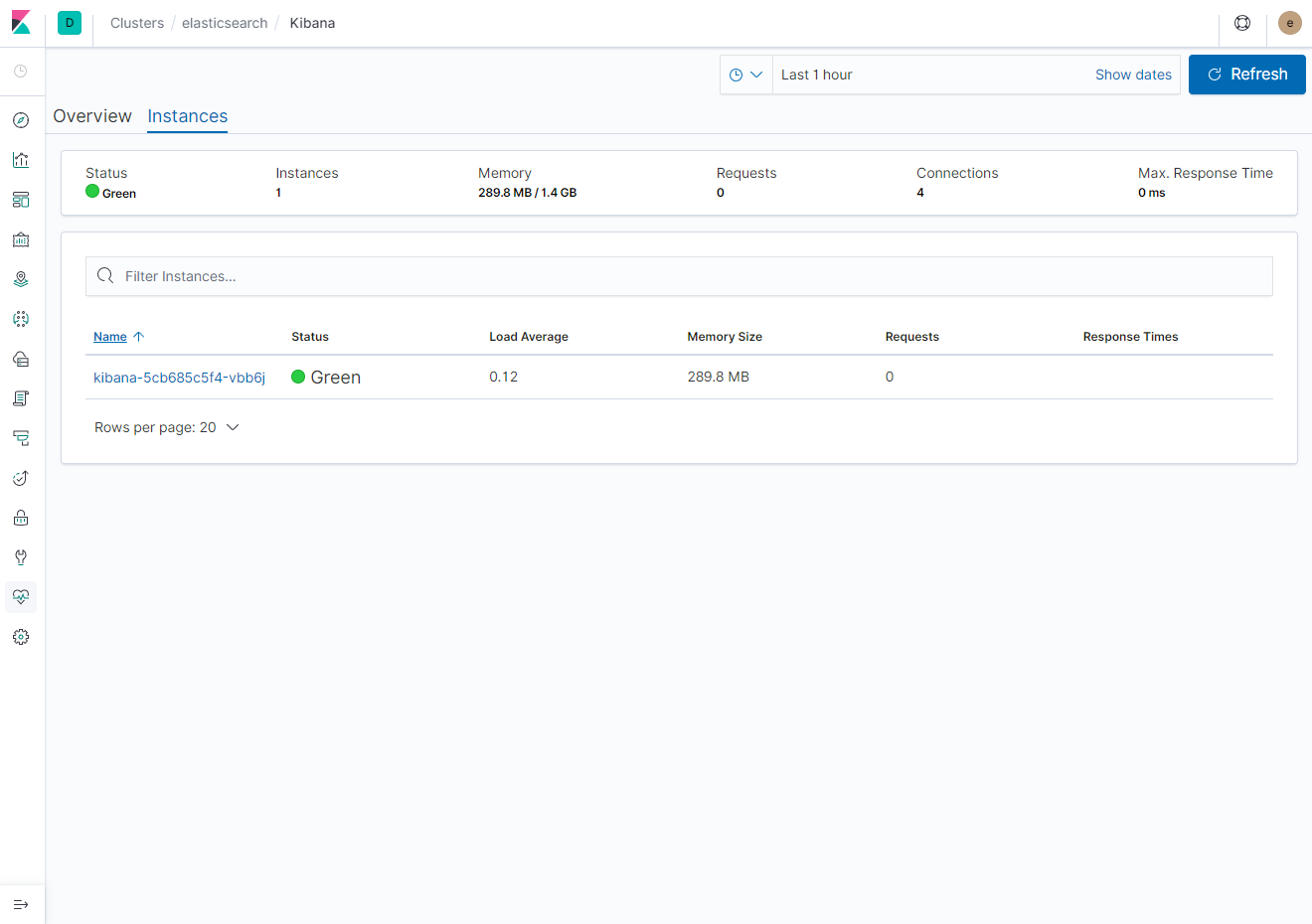
- Instances
Fluentd 구축
- Fluentd 생성
- 로그 수집 확인
- index 생성
a. Fluentd 생성
> fluentd-config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: kube-logging
data:
fluent.conf: |
<match fluent.**>
# this tells fluentd to not output its log on stdout
@type null
</match>
# here we read the logs from Docker's containers and parse them
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/app.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
# we use kubernetes metadata plugin to add metadatas to the log
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
# we send the logs to Elasticsearch
<match **>
@type elasticsearch_dynamic
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
reload_connections true
logstash_format true
logstash_prefix logstash
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 32
overflow_action block
</buffer>
</match>Fluentd는 Input(source) > Filter(filter) > Buffer(buffer) > Output(match) 순으로 처리된다고 볼 수 있다.
- source : 수집 대상 정의
- source.@type : 수집 방식 정의. tail은 파일을 tail하여 읽어오는 방식
- source.pos_file : 수집 파일의 inode를 추적하기 위한 파일로 마지막 읽은 위치 기록
- source.parse.@type : 전달 받은 데이터를 파싱. json 타입으로 파싱하여 전달. 정규표현식이나 별도의 가공하지 않고 전달할 수 도 있음
- filter : 특정 필드에 대한 필터링 조건을 정의. grep, parser 등을 지정할 수 있으며, kubernetes_metadata를 사용하기 위해 별도의 plugin을 설치하여 구성
- match : 출력할 로그 형태 정의. stdout, forward, file 등을 지정할 수 있으며, elasticsearch_dynamic으로 지정하면, 유동적으로 선언하여 처리할 수 있음
- match.buffer : input 에서 들어온 log를 특정데이터 크기 제한까지 도달하면 output 출력
> fluentd-daemonset.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
namespace: kube-logging
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd # if RBAC is enabled
serviceAccountName: fluentd # if RBAC is enabled
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.1-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-client.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_ELASTICSEARCH_USER # even if not used they are necessary
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD # even if not used they are necessary
valueFrom:
secretKeyRef:
name: elasticsearch-pw-elastic
key: password
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluentd-config
mountPath: /fluentd/etc # path of fluentd config file
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluentd-config
configMap:
name: fluentd-config # name of the config map we will create> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f fluentd-config-map.yaml -f fluentd-daemonset.yaml
configmap/fluentd-config created
serviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.apps/fluentd created
[root@ip-192-168-78-195 efk]#> 확인
[root@ip-192-168-78-195 efk]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-578dd48f84-8trwh 1/1 Running 0 54m
elasticsearch-data-0 1/1 Running 0 54m
elasticsearch-master-745c995d88-mk9qs 1/1 Running 0 54m
fluentd-lnzhw 1/1 Running 0 26s
fluentd-vzxvg 1/1 Running 0 27s
kibana-5cb685c5f4-vbb6j 1/1 Running 0 52m
[root@ip-192-168-78-195 efk]#b. 로그 수집 확인
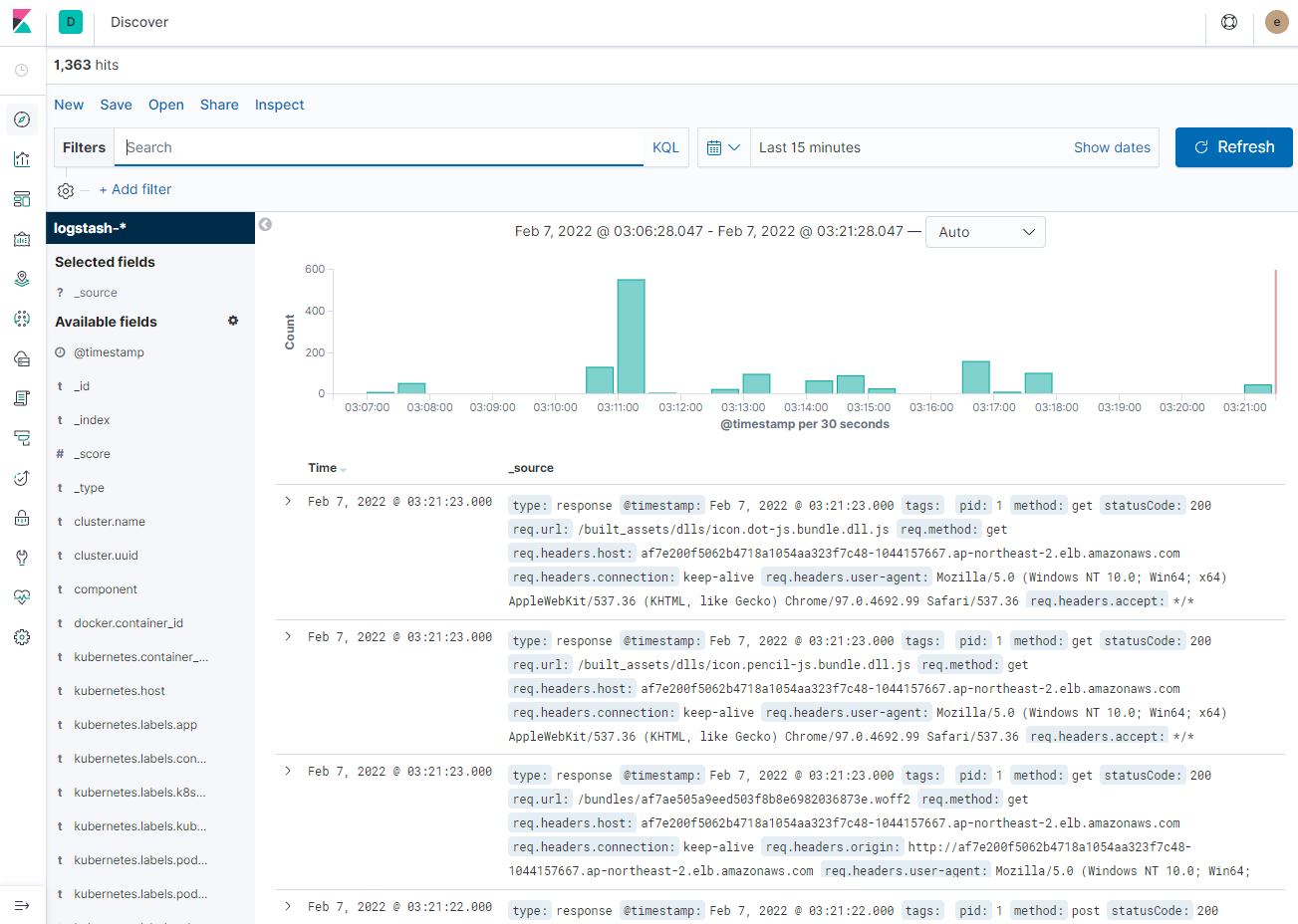
FluentD를 커스터마이징 하기 전에 Log 수집여부를 확인해 보도록 하자.

위와 같이 default로 logstash-*로 시작하는 index pattern이 추가되어 있는 것을 확인할 수 있다.
c. index 생성
fluentd-plugin-kubernetes_metadata_filter를 사용하여 kubernetes.metadata를 활용할 수 있다. 해당 플러그인은 이미 이미지에 포함되어 있거나, gem install을 이용하여 수동 설치한 커스텀이미지를 생성할 수 있다.
본 포스팅에서 사용한 fluent/fluentd-kubernetes-daemonset:v1.1-debian-elasticsearch에는 이미 플러그인이 설치되어 있어 별도로 커스텀할 필요는 없다.
> fluentd-config-map-custome-index.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: kube-logging
data:
fluent.conf: |
<match fluent.**>
# this tells fluentd to not output its log on stdout
@type null
</match>
# here we read the logs from Docker's containers and parse them
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
# we use kubernetes metadata plugin to add metadatas to the log
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match kubernetes.var.log.containers.**kube-logging**.log>
@type null
</match>
<match kubernetes.var.log.containers.**kube-system**.log>
@type null
</match>
<match kubernetes.var.log.containers.**monitoring**.log>
@type null
</match>
<match kubernetes.var.log.containers.**infra**.log>
@type null
</match>
# we send the logs to Elasticsearch
<match kubernetes.**>
@type elasticsearch_dynamic
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
reload_connections true
logstash_format true
logstash_prefix ${record['kubernetes']['pod_name']}
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 32
overflow_action block
</buffer>
</match>Default ConfigMap과의 두가지 구성을 추가/변경하였다.
> index pattern 변경
- Default ConfigMap : <match **> / logstash_prefix logstash
- Custom ConfigMap : <match kubernetes.**> / logstash_prefix ${record['kubernetes']['pod_name']}
Kuberentes Metadata를 사용하여 pod_name으로 index를 생성한다. 이와 같은 index로 활용 가능한 Kubernetes Metadata는 pod_name은 물론 namespace_name, container_name 등을 사용할 수 있다. 추가 시 logstash_prefix를 나열하여 처리할 수 있다.
> 로그 출력 제외대상 추가
- <match kubernetes.var.log.containers.**kube-logging**.log>
@type null
</match>
<match kubernetes.var.log.containers.**kube-system**.log>
@type null
</match>
<match kubernetes.var.log.containers.**monitoring**.log>
@type null
</match>
<match kubernetes.var.log.containers.**infra**.log>
@type null
</match>
Fluentd에서 ElasticSearch로 전송할 로그 대상 중 제외하고자 하는 로그 형태를 정의한다.
> 반영
[root@ip-192-168-78-195 efk]# kubectl apply -f fluentd-config-map-custome-index.yaml
configmap/fluentd-config configured
[root@ip-192-168-78-195 efk]# kubectl rollout restart daemonset/fluentd -n kube-logging
daemonset.apps/fluentd restarted
[root@ip-192-168-78-195 efk]#> 확인
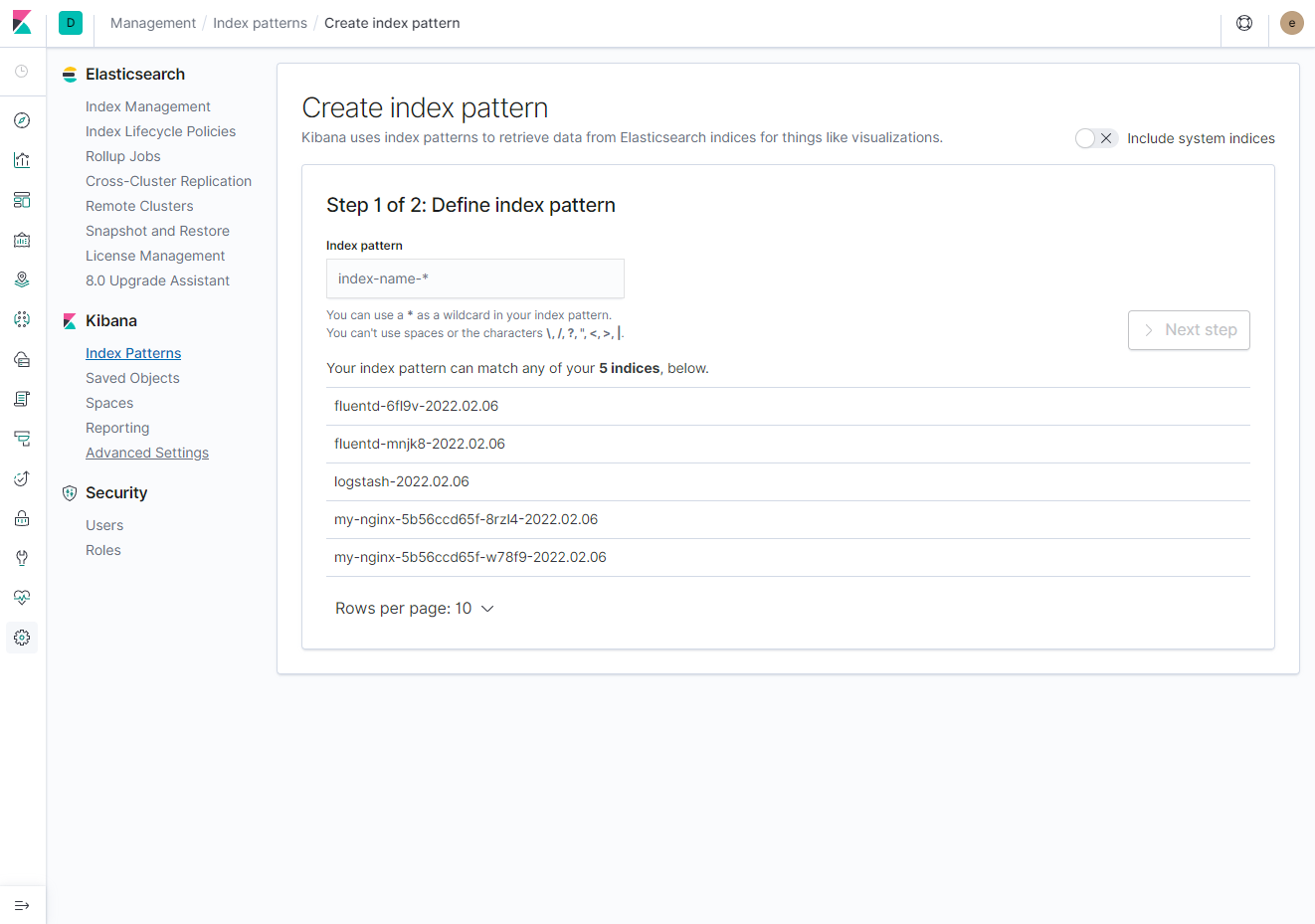
위와 같이 index pattern에 logstash 이외에 pod_name으로 기동되는 my-nginx-* pod가 추가되었다. index를 추가하고 Discover에서 아래와 같이 확인이 가능하다.
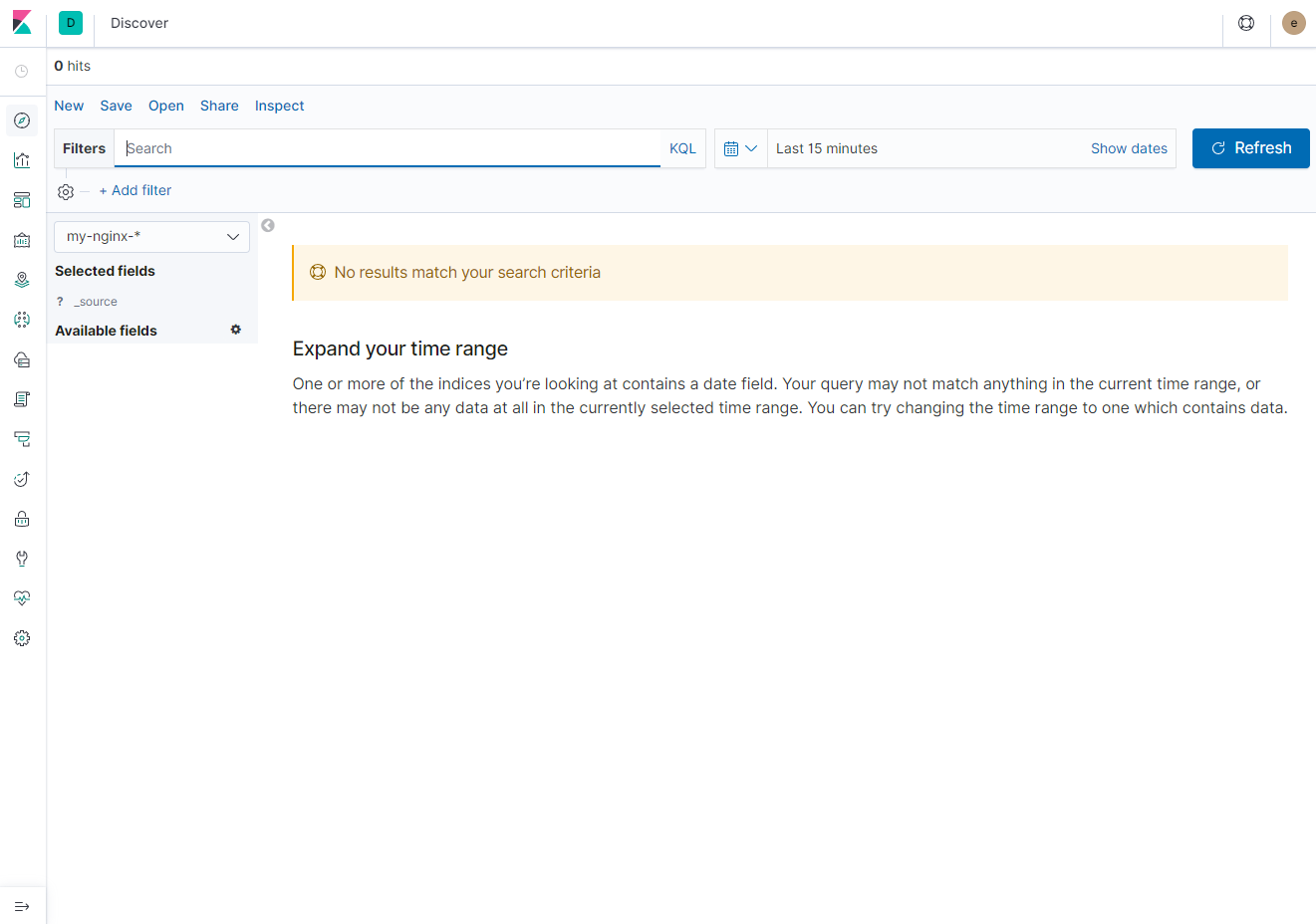
위와 같이 아직 데이터 수집이 이뤄지지 않은 상태로 아래와 같이 호출 후 재 확인해 보도록 하자.

아래와 같이 2회 호출 후 Refresh를 확인해 보면 로그가 출력되는 것을 확인할 수 있다.
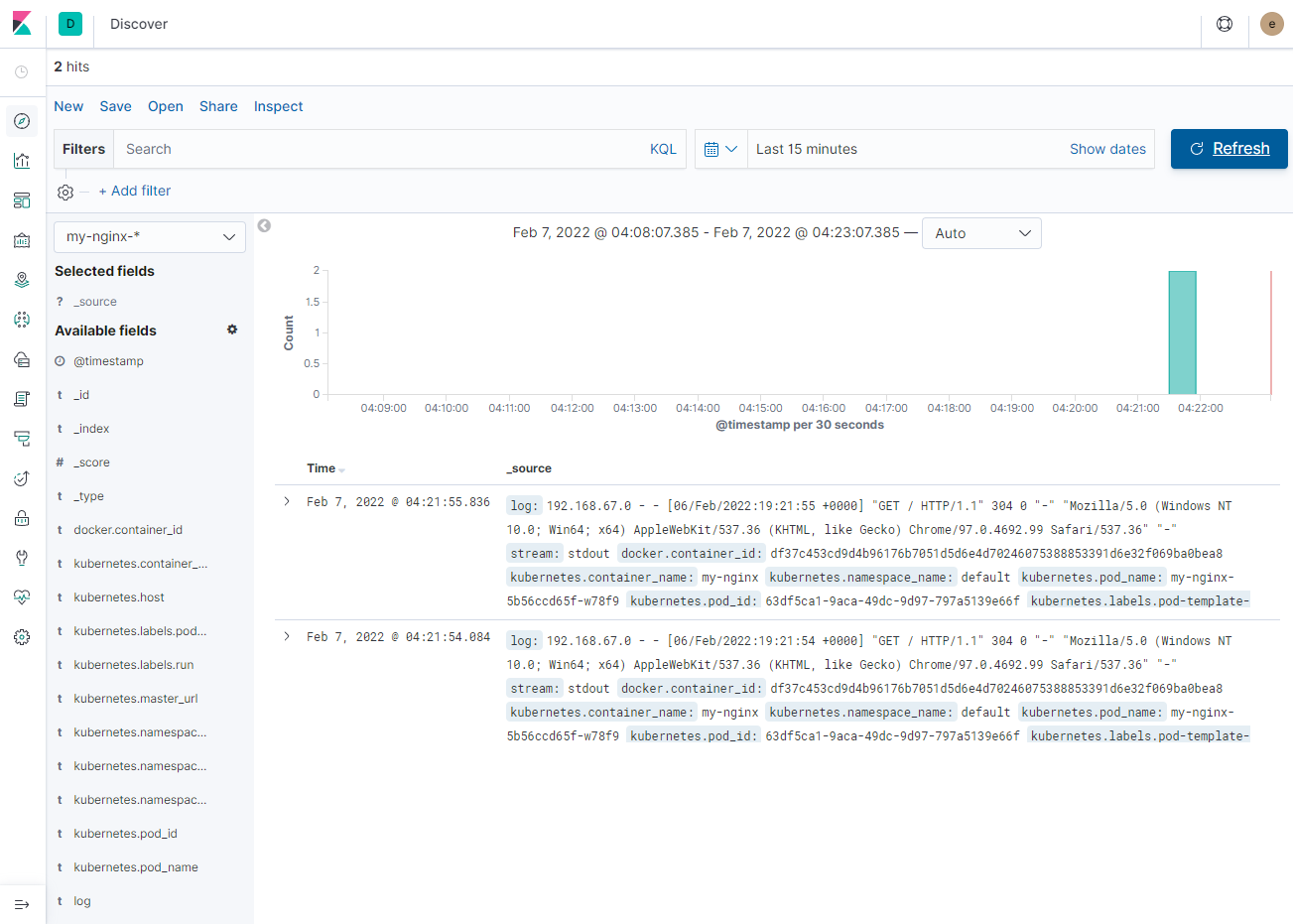
또한, 앞서 로그 수집대상으로 정의한 logstash를 확인해 보면,
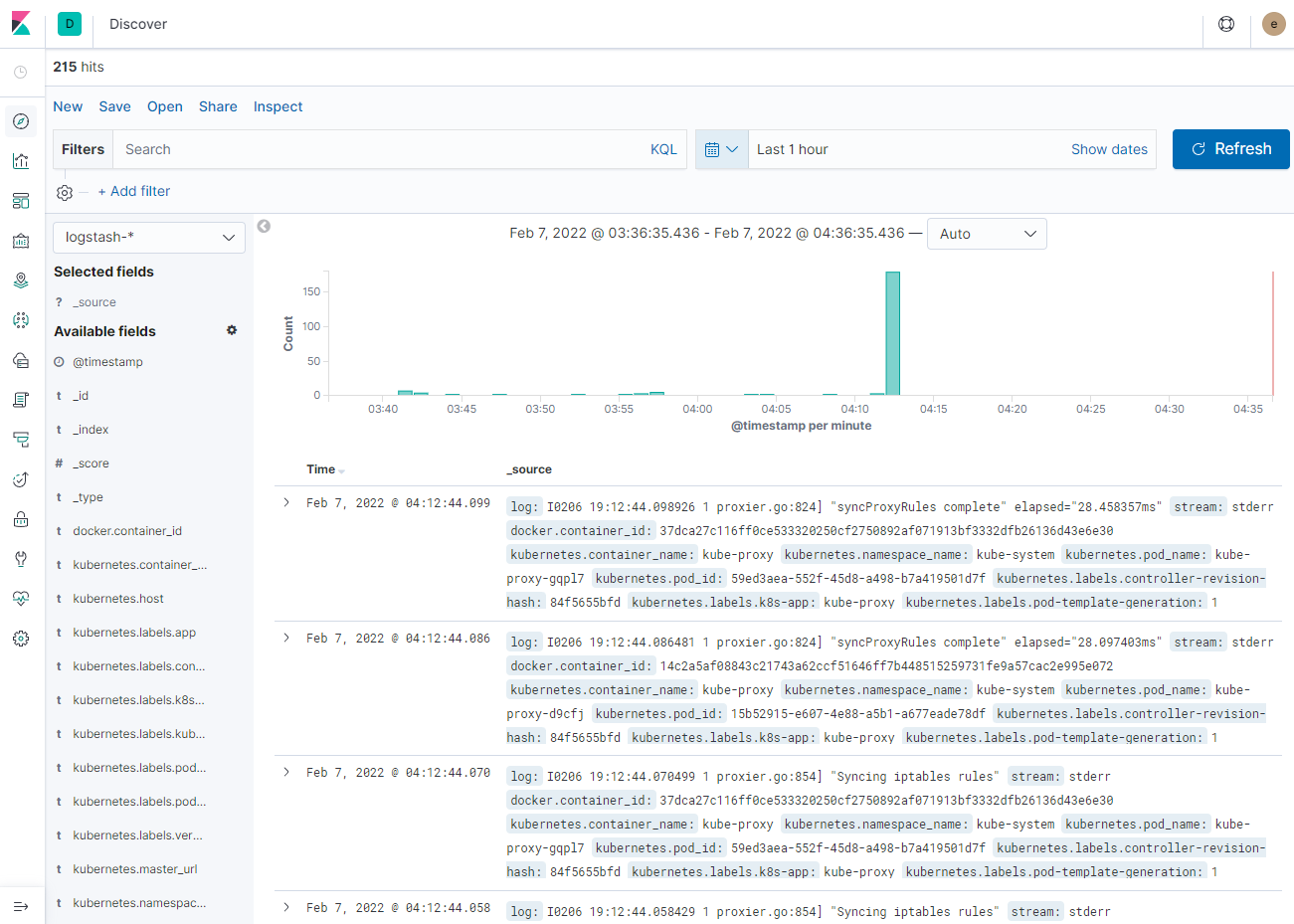
위와 같이 configmap이 반영된 시점 이후부터 logstash에 매핑되어 있던 index 정보들은 더이상 수집되지 않는 것을 확인할 수 있다.
마지막으로 추가 어플리케이션을 추가하여 수집되는지 여부를 확인해 보도록 하자. 테스트 방식은 동일한 nginx deployment를 수집 제외 대상으로 정의한 kube-logging namespace 내에 배포하고, 다른 nginx deployment는 app-test라는 namespace에 배포해 보도록 하자.
> kube-logging namespace 내 nginx service
apiVersion: v1
kind: Service
metadata:
name: my-nginx
namespace: kube-logging
labels:
run: my-nginx
spec:
ports:
- nodePort: 30080
port: 80
protocol: TCP
type: NodePort
selector:
run: my-nginx> kube-logging namespace 내 nginx deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
namespace: kube-logging
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80> app-test namespace 내 nginx service
apiVersion: v1
kind: Service
metadata:
name: my-nginx
namespace: app-test
labels:
run: my-nginx
spec:
ports:
- nodePort: 30280
port: 80
protocol: TCP
type: NodePort
selector:
run: my-nginx> app-test namespace 내 nginx deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
namespace: app-test
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80아래와 같이 pod 상태를 확인해 보자.
[root@ip-192-168-78-195 app]# kubectl get pod --all-namespaces | grep my-nginx
app-test my-nginx-5b56ccd65f-j79sb 1/1 Running 0 7m33s
app-test my-nginx-5b56ccd65f-j8dmq 1/1 Running 0 7m33s
default my-nginx-5b56ccd65f-8rzl4 1/1 Running 0 2d11h
default my-nginx-5b56ccd65f-w78f9 1/1 Running 0 2d11h
kube-logging my-nginx-5b56ccd65f-7fgmx 1/1 Running 0 10m
kube-logging my-nginx-5b56ccd65f-shc9z 1/1 Running 0 10m
[root@ip-192-168-78-195 app]#정상 Running 상태로 기동이 되었다면, 각각 페이지 정상 호출 여부를 확인하고, 아래와 같이 kibana index pattern을 확인해 보자.
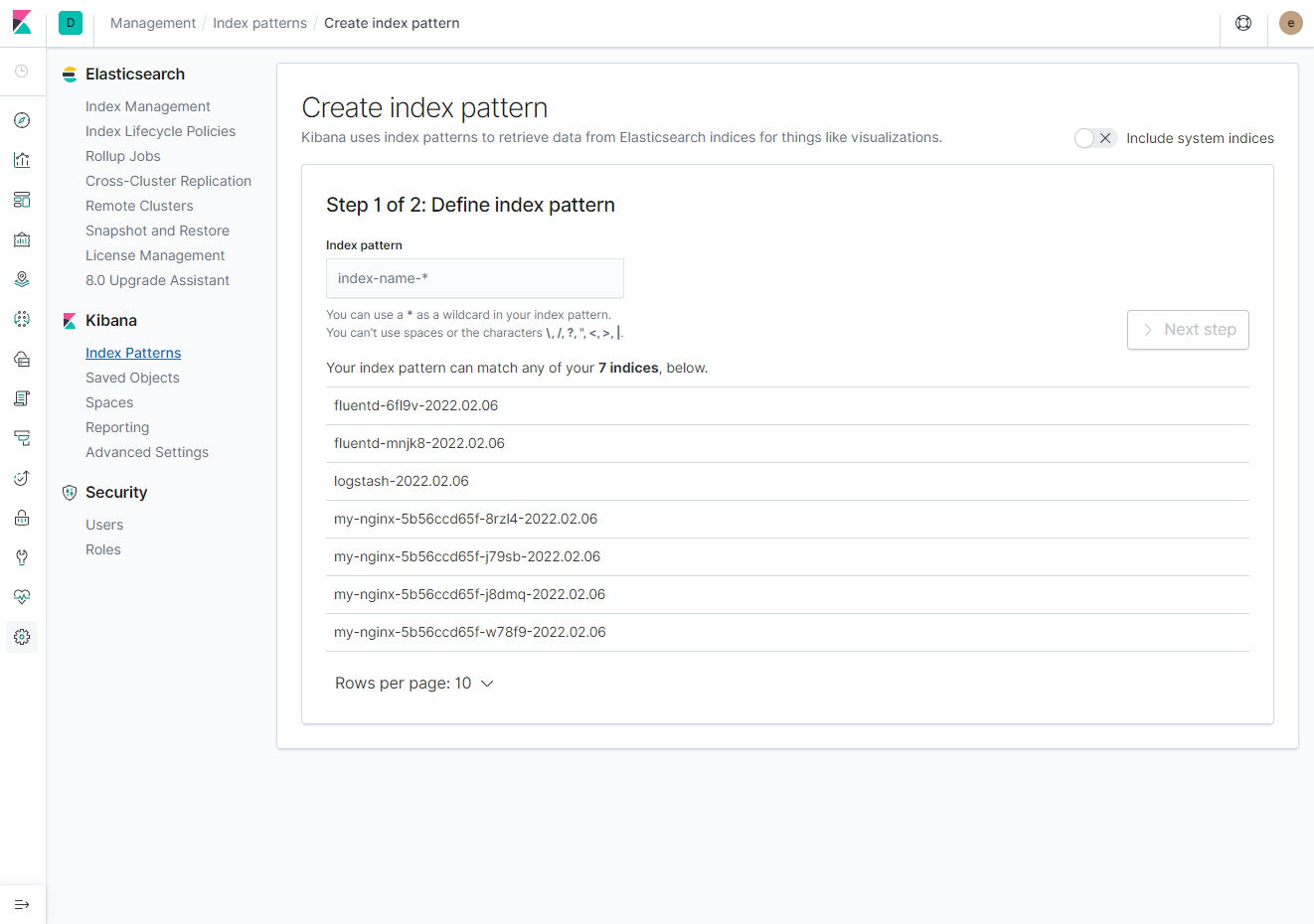
위와 같이 기존 default namespace 내의 pod와 app-test에 추가된 nginx pod만 index pattern에 추가된 것을 확인할 수 있다. kube-logging에 추가된 nginx pod는 수집 대상에서 제외되었다.
결론
본 포스팅에서는 Fluentd를 활용하여 수집, 정제 방안에 대해 알아보았으며, ElasticSearch가 제공하는 ILM 정책(용량, 기간)에 따라 HOT, WARM, COLD, FROZEN 아카이브로 구분하여 관리하는 저장소 체계 설계 및 Kibana의 트래픽 모니터링, 구간별 이상징후 탐지 기능, 거래 추적 등에 대한 보다 시각화가 강조된 대시보드 생성과정 등에 대해서는 별도 포스팅에서 다뤄보도록 하자.
지금까지 ElasticSearch를 활용한 Kubernetes 로깅 환경 구성 방안에 대해 알아보았다. ElasticSearch를 활용하여 데이터를 수집하고, 저장하고, 분석하는 과정은 마이크로서비스 환경에서 반드시 선행되어야 할 부분이다. 특히 로깅의 경우 개발 초기 단계부터 활용 가능한 Telemetry 요소이므로 환경 구성 초반에 반드시 구성하여 활용 가치를 높여 나가도록 하자.
'③ 클라우드 > ⓜ MSA' 카테고리의 다른 글
| 마이크로서비스로의 점진적 전환 시 고려사항 (6) | 2021.12.04 |
|---|---|
| 마이크로서비스 분산 트랜잭션 관리 (Saga Pattern) (5) | 2021.11.23 |
| 마이크로서비스 분산 트랜잭션 관리 (2Phase Commit) (1) | 2021.11.23 |
| 마이크로서비스 Schema 분리 설계 (테이블 분리, 외래키 참조관계, 조인, 데이터 정합성 보장) (0) | 2021.11.22 |
| 마이크로서비스 데이터베이스 분리 설계 (0) | 2021.11.22 |
- Total
- Today
- Yesterday
- aa
- openstack token issue
- JBoss
- 쿠버네티스
- webtob
- aws
- SWA
- Da
- openstack tenant
- nodejs
- TA
- 오픈스택
- kubernetes
- 마이크로서비스
- SA
- k8s
- Docker
- wildfly
- 아키텍처
- 마이크로서비스 아키텍처
- jeus
- JEUS6
- OpenStack
- Architecture
- apache
- node.js
- API Gateway
- git
- MSA
- JEUS7
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |