
티스토리 뷰
개요
앞선 포스팅에서 마이크로서비스 환경의 데이터베이스 분리 기준에 대해 알아보았다. 모놀리식 어플리케이션을 마이크로서비스 아키텍처로 전환하기 위해서는 단일DB를 분산DB 형태로 분리해 나가야 한다. 물론 한번에 모든 DB를 서비스 별로 쪼개는 것은 리스크를 확대시킬 수 있다. 서비스간 결합도가 낮은 마이크로서비스로부터 하나씩 DB를 분리해 나가면서 점진적 결합도를 낮추는 것이 무엇보다 중요하다는 점을 기억하고 다음 포스팅을 읽어주었으면 한다.
- 마이크로서비스 아키텍처의 기준과 DB 분리 : https://waspro.tistory.com/718
데이터베이스의 분리는 단순하게 DB의 스키마를 나누는데에 그치지 않는다. 하나의 프로젝트에서 분석/설계라는 과정을 거쳐 어플리케이션과 테이블, 인터페이스를 정의하고 이를 개발에 적용하는데, 특히 테이블 설계는 데이터를 정의하는 측면에서 어플리케이션과 인터페이스가 정의된 후 가장 후순으로 진행하게 된다.
어플리케이션(API)의 변화와 인터페이스의 변화는 개발과정에서 감당할 수 있는 수준의 변화라 할 수 있지만, 데이터의 변화는 마이크로서비스 전체를 재설계 해야할 수 있는 중대한 변화라 할 수 있다. 따라서 초기 데이터의 변화를 정확하게 파악하고, 비즈니스를 개선해 나가는 것은 무엇보다 중요한 과정이다.
마이크로서비스에서 데이터베이스를 분리하기 위해서는 일반적으로 아래와 같은 고려사항을 검토해야 한다.
- 데이터 동기화 문제
- 논리적 스키마 대 물리적 스키마 분해
- 트랜잭션 무결성
- 조인
- 대기 시간
지금부터 총 7번의 포스팅으로 데이터베이스를 분리하기 위한 고려사항들을 하나씩 되짚어보고, 다양한 분산DB 설계 패턴들에 대해 알아보도록 하자.
단일 DB 패턴
우리는 분산DB 설계 패턴을 알아보기 전에 먼저 모놀리스 어플리케이션 내 단일 DB 환경의 문제점에 대해 알아보자.
기존 모놀리식 어플리케이션을 마이크로서비스 아키텍처로 전환함으로써 여러 고려사항에 맞닫들이게 된다. 특히 여러 서비스 간 데이터 공존과 관련된 문제를 해소해 나가야 한다. 대표적인 단일 DB의 문제점은 다음과 같다.
- 마이크로서비스 간 정보 보호(은닉)의 어려움
- 데이터 통제의 어려움
- 결합도 증가에 따른 서비스 배포 독립성 확보 불가
설계 패턴 1. 마이크로서비스 간 독립 DB 사용
각 마이크로서비스가 자체 데이터를 소유하고 비즈니스를 서비스 내에서 처리할 수 있도록 데이터베이스를 분할하는 것은 어렵지만 가장 고객이 선호하는 패턴이라 할 수 있다.
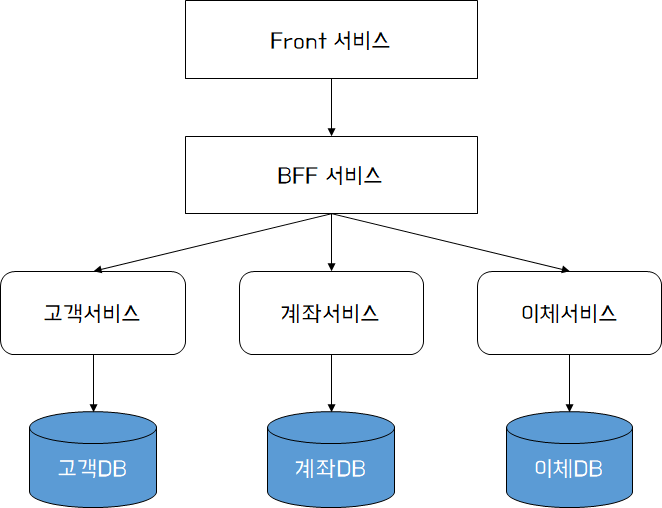
신규 서비스를 위와 같은 형태로 설계하는 것은 가장 바람직한 설계 방법이다. 다만, 현행 서비스가 존재하고 이를 마이크로서비스로 전환하는 경우 데이터의 결합도를 끊어 낼 수 있도록 완벽하게 설계하는 것은 굉장히 어려운 일이다. 위와 같이 설계하기 위해서는 비즈니스의 대부분을 수정하여 서비스를 재 분류하는 작업부터 시작되어야 한다.
각 서비스가 독립적인 스키마를 갖도록 설계할 경우 서비스간 결합도는 현저히 낮아져 각 서비스가 추구하는 목표에 맞게 서비스를 설계할 수 있을 것이다. 그 목표가 성능일 수도, 잦은 배포의 독립성일 수도, 비즈니스 요구사항일 수도 있으며, 독립된 데이터를 갖는 것은 바로 이 목표를 달성하기 위한 충분조건이라 할 수 있다. 다만 스키마의 분리가 쉽지 않기 때문에 모든 서비스를 한번에 전환하는 것보다는 순서를 정하고 분리해 나가는 것이 좋다.
설계 패턴 2. 데이터 공유 방식 (View)
완전한 분리가 불가능하다면, 차선으로 서비스당 2개 이상의 데이터베이스에 접근하는 방법을 선택할 수 있다. 특히 서로 다른 서비스가 독립적인 DB를 갖고, 그 서비스간 데이터 조회를 고려해야 할 경우 테이블에 직접 접근하기 보다는 View를 사용하여 결합도를 낮출 수 있다. View를 사용함으로써 서비스에 표시되는 데이터를 제한하여 액세스해서는 안 되는 정보를 은닉할 수 있다.
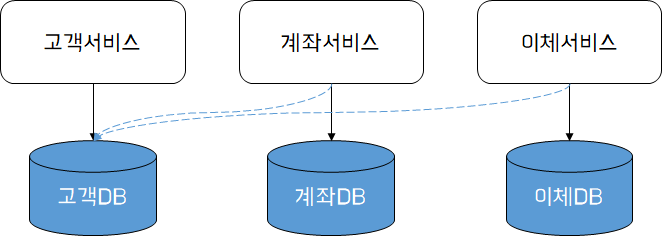
위는 타 서비스의 데이터소스에 직접 접근하는 형태의 조회 방식이다. 위와 같이 구성할 경우 공유하는 서비스간 결합도가 높아지는 문제가 발생할 수 있다. 고객 서비스의 고객 DB가 변경될 경우 계좌서비스와 이체서비스는 변경된 데이터 또는 스키마에 대한 검증을 함께 수행해야 한다.
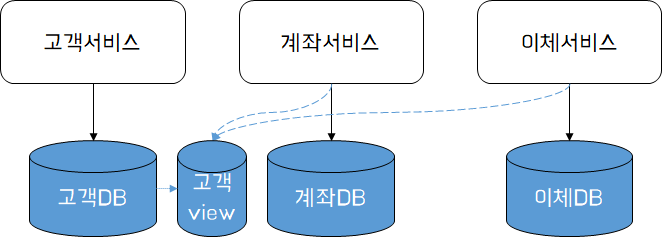
이를 해소하기 위해 고객 DB에 접근하고자 하는 모든 외부 서비스를 위한 고객DB 전용 View 스키마를 만들고 외부 서비스가 대신 해당 스키마를 바라보도록 설계한다. 이를 통해 View가 유지되는 한 고객DB의 자체 스키마를 변경할 수 있다. 또한, 불필요한 데이터를 숨기거나, 데이블 조인을 수행한 후 View로 제공할 수 있다.
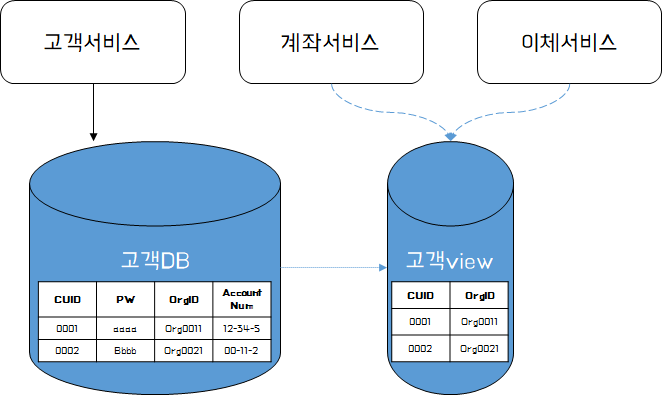
다만, View를 활용할 경우 장단점이 존재한다. View는 일반적으로 캐시를 사용하여 미리 계산된다. 즉, View에서 데이터를 읽기 원하는 계좌서비스, 이체서비스는 View에서 매번 고객DB에서 데이터를 읽어올 필요가 없으므로 성능이 향상될 수 있다. 반면에 View에서 오래된 데이터를 읽을 수 있음을 고려해야 한다. 즉, View를 갱신하는 방식이 성능과 데이터 정합성 사이에서 중요하다는 점을 인지하고 설계해야 한다.
이와 같이 View를 설계하기 위해서는 몇가지 제약조건이 존재한다. 먼저 앞서 잠시 언급한 캐시를 사용하는 것과 같이 정합성의 이슈가 발생할 수 있다.(ReadOnly의 전형적인 이슈) 두번째로 고객DB와 고객View가 Schema는 분리되더라도 동일한 데이터베이스 엔진 내에 있어야 한다는 점이다. 즉 데이터베이스에 직접 접근하는 방식보다는 결합도를 낮출 수 있지만, 여전히 CUD와 R이 하나의 데이터베이스 내에서 발생한다는 점은 인지해야 한다.
데이터 공유 방식(View) 패턴은 단일 DB 내 계정이 분리되어 있는 환경 또는 현행 스키마를 모델링을 통해 분해하기 어려운 경우에 적용하기 용이하다. 물론 View는 여전히 서비스간 일부 결합도가 존재하기 때문에 최종 데이터베이스의 형태라 볼수는 없지만, 데이터 모델링에 들어가는 에포트가 너무 클 경우에는 한번쯤 고려해 볼 수 있는 패턴이 아닐까 싶다.
설계 패턴 3. 공통 마이크로서비스 활용
앞서 각 서비스가 명확히 자신의 데이터만을 관리하고 서비스할 수 있다면 가장 좋은 설계라고 이야기 했다. 물론 현실적으로 굉장히 어려운 방식이지만, 이를 구현하기 위해 또 하나의 공통 서비스를 생성하고 Shared Data를 관리하는 방식을 고려해 볼 수 있다.
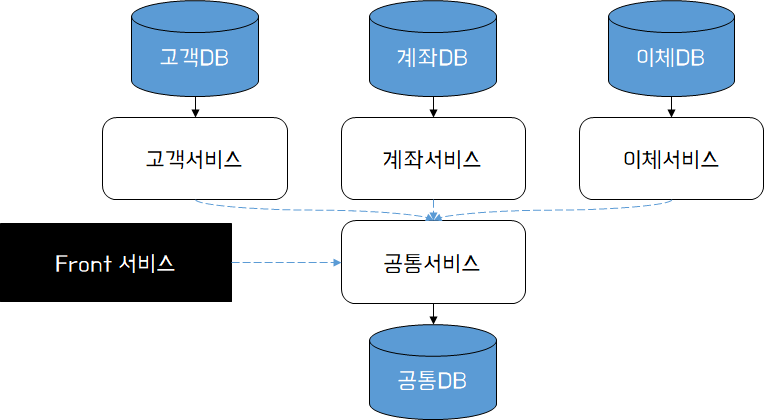
즉 고객/계좌/이체 서비스에서 개별적으로 사용하는 데이터는 각 서비스의 DB에 저장하고, 공통으로 사용하는 데이터 또는 상호 공유되어야 하는 데이터를 공통서비스 내 공통DB에 저장한다. 공통서비스는 Front 서비스에게 공통 데이터를 직접 액세서 할 수 있도록 엔드포인트를 제공하고, 마이크로서비스 간에는 공통 데이터 또는 공유 데이터를 조회할 수 있는 API를 제공한다. 고객/계좌/이체(호출자) 서비스는 DB에 직접 액세스 하지 않고 API를 호출하여 결과를 전달 받는 방식으로 구현한다.
대체로 해당 패턴은 최종 모습은 아니지만, API 형태로 서비스를 호출하여 Schema를 분리하기 위한 초입단계로써 적용해 볼 수 있을 것이다.
설계 패턴 4. ReadOnly DB 활용
다음으로 타 마이크로서비스의 데이터를 CUD하는 경우 API, 조회는 ReadOnly DB를 이용하는 방식이다.
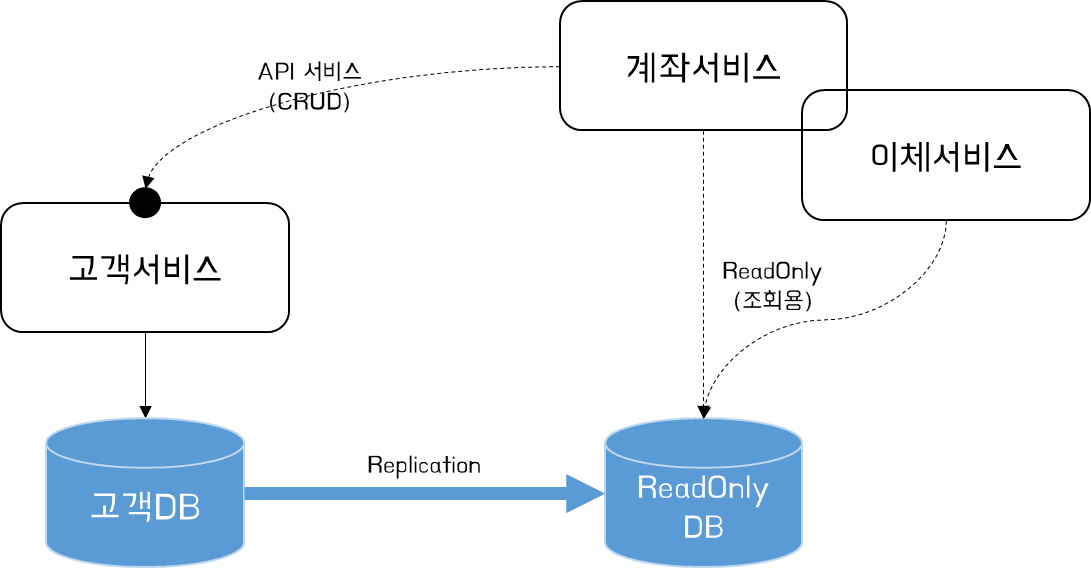
계좌서비스는 고객서비스에 데이터 변경을 위해 고객 API를 호출한다. 이때 고객DB에 변경된 데이터는 ReadOnly DB로 복제되며, 고객서비스를 조회할 경우 이 ReadOnly DB를 통해 접근할 수 있다. 이때 복제를 구현할 수 있는 방안들은 공통적으로 타이밍 이슈가 발생할 수 있다는 점을 염두해 두고 아키텍처를 설계해야 하며, 업데이트 된 시점을 응용관점에서 관리해 주는 것도 좋은 방법이 될 수 있다.
복제 방법은 DB에서 지원하는 Replication 방식을 사용할 수도 있지만, 이기종 DB간 지원, Schema 변경에 대한 대응을 위한 Oracle GoldenGate(OGG), Debezium 등과 같은 CDC 도구를 사용하는 것이 안정적이다.
ReadOnly DB를 적용하면, 데이터를 보호하고, 읽기 전용 NoSQL DB를 활용하여 성능상 이점을 가져갈 수 있다. 특히 분산DB 데이터 관리 방안으로 CQRS나 API Composition을 위한 조회 용도의 DB로 활용하기 좋다.
결론
오늘은 첫 시간으로 분산 DB 환경에서 상호간 데이터 조회를 효율적으로 할 수 있는 4가지 패턴에 대해 알아보았다.
- 설계 패턴 1. 마이크로서비스 간 독립 DB 사용
- 설계 패턴 2. 데이터 공유 방식 (View)
- 설계 패턴 3. 공통 마이크로서비스 활용
- 설계 패턴 4. ReadOnly DB 활용
설계 패턴 1의 경우 이상적인 마이크로서비스 환경 상의 분산 DB 형태이지만, 이는 비즈니스 처리 흐름에 따라 현실적으로 어려운 구성이다.
설계 패턴 2의 경우 DB에 접근하기 보다는 불필요한 데이터를 제한하도록 View를 사용하는 방식을 적용할 수 있지만, 물리적으로 동일한 DB 내에 Table과 View가 함께 공존한다는 차원에서 결합도가 완전히 분리되었다고 보기 어렵다.
설계 패턴 3의 경우 독립성을 현저히 낮춰 줄 수 있는 API 호출 방식으로 가장 선호하는 방식이다. 마이크로서비스 아키텍처를 구성해 나가기 위한 구성 요소로 Rest API를 이야기 하는 이유도 바로 이와 무관하지 않다. 독립적인 DB에 대한 조회는 특히 실시간성 조회가 강조되는 경우 API를 통해 조회하도록 설계하는 것이 좋다.
마지막 설계 패턴 4의 경우 2와 비슷하다고 볼 수 있지만, 물리적으로 독립된 환경에 Replication을 구성할 수 있어 보다 안정적인 서비스 제공이 가능하다. 특히 마이크로서비스 환경에서 CQRS DB 등을 적용하기 위한 패턴으로 적합핟. 다만, 데이터 정합성에 보다 노력을 기울여야 한다.
다음 포스팅에서는 모놀리식 to 마이크로서비스 DB로의 전환 시 데이터 분할 방법에 대해 알아보도록 하자.
'③ 클라우드 > ⓜ MSA' 카테고리의 다른 글
| 마이크로서비스 데이터베이스 분리 설계 (0) | 2021.11.22 |
|---|---|
| 마이크로서비스 분산DB 데이터 분할, 동기화 설계 (0) | 2021.11.21 |
| 마이크로서비스 아키텍처의 기준과 DB 분리 (7) | 2021.09.11 |
| 성공적인 DevSecOps 구현하기 (0) | 2021.03.19 |
| Microservice Architecture API Composition (0) | 2020.10.04 |
- Total
- Today
- Yesterday
- jeus
- JEUS6
- 쿠버네티스
- aws
- JBoss
- kubernetes
- 마이크로서비스
- wildfly
- JEUS7
- Da
- apache
- openstack token issue
- 오픈스택
- openstack tenant
- 마이크로서비스 아키텍처
- node.js
- k8s
- SA
- aa
- 아키텍처
- TA
- MSA
- Architecture
- OpenStack
- Docker
- API Gateway
- webtob
- nodejs
- SWA
- git
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |