
티스토리 뷰
이번 포스팅에서는 클라우드 환경에서 적용 가능한 다양한 아키텍처들의 뒤를 묵묵히 지키고 있는 Telemetry 요소들에 대해 살펴보겠습니다.
# 본 포스팅은 개인적으로 또는 회사 차원에서 진행한 TF의 다양한 학습 결과 그리고 Architecting On AWS 교육 등을 통해 습득한 지식을 리마인드하며 공유하는 것임을 알려드립니다.
탄력성을 위한 요소들, 고가용성 및 장애 복구 정책, 모니터링, 로깅, 추적 등을 위한 도구들의 모음과 자동화 방책 등을 간단히 나마 파악해보고 어떻게 대처해 나가야 할지 고민해 보도록 하겠습니다.
이번 포스팅에서 말하고 싶은 키 포인트는 바로 자동화!
일반적으로 고가용성을 유지해야 한다고 하면 어떠한 요건들이 성립해야 될까요?
1) 내결함성 : 애플리케이션 구성 요소의 내장된 중복성
2) 확장성 : 애플리케이션의 설계 변경 없이 성장을 수용하는 능력
3) 복구성 : 재해 발생 후 서비스 복구와 관련된 프로세스, 정책 및 절차
AWS에서는 ELB, Auto Scaling Group을 통해 이와 같은 고가용성 아키텍처를 설계할 수 있습니다.
1. 탄력성
또한 탄력적인 인프라는 용량 요구사항을 산정하는데 시간을 들이지 않고 보다 중요한 요소에 집중할 수 있게 해주는 요소입니다. 지능적으로 확장 및 축소가 가능하여 자동화 된 인프라 관리가 가능해집니다.
1) 트래픽 급증 시 웹 서버 수 증가
2) 트래픽이 줄어들 때 데이터베이스의 쓰기 용량 감소 (IOPS : Input/Output Operations Per Second)
3) 아키텍처 전반에 걸친 일상적인 수요 변동 처리
탄력성에는 크게 두가지 유형이 있는데
1) 시간 기반 탄력성
- 리소스가 사용되지 않을 때 리소스 끄기 (개발 및 테스트 환경)
2) 볼륨 기반 탄력성
- 수용 강도에 맞게 규모 조정
2. 모니터링
마이크로 서비스와 클라우드 서비스에서 모니터링이 중요한 이유는 별도로 설명할 필요의 여지가 없을 정도로 그 가치가 충분하고 끊임없는 모니터링 및 추적을 위한 다양한 솔루션을 검토하고 반영하는 노력을 기울여야 합니다.
기존 모놀로식 아키텍처에서 단순히 한/두대 또는 수십대의 고정된 인프라를 감시하던 상황에서 지금은 정해지지 않은 인프라 속에서 탐색하고 판단하여 서비스의 정상 유무를 진단하고 라우팅하는 일련의 과정들이 모니터링 되어야 하는 복잡한 구조로 변경되고 있습니다.
특히 고정되지 않은 인프라 정보를 모니터링하기 위한 기술들이 나타나고 있고 기존 APM을 개발하던 회사들은 물론 API Gateway 등에 APM 기능까지 탑재하여 운영하는 APIM 플랫폼까지 등장하고 있는 추세입니다.
일반적으로 Telemetry 영역으로 구분할때, 로깅, 모니터링, 추적을 기준으로 설명을 하지만 이번 포스팅에서는 모니터링 부분에 중점을 두고 설명하도록 하겠습니다.
모니터링은 운영상태, 리소스 활용, 애플리케이션 성능, 보안 감사 등을 위해 반드시 필요한 필수 요소입니다.
- Cost Explorer : 비용 지출 관련 정보 (보고서 생성, 13개월 데이터, 예측 제공, 지출 패턴 참조)
- Amazon CloudWatch : 리소스에 대한 지표 수집, 경보 생성 및 알람, 용량 변화 트리거
Amazon CloudWatch
CloudWatch는 총 6가지 기준으로 (지표, 로그, 경보, 이벤트, 규칙, 대상) 모니터링할 수 있습니다.

1) 지표 : 15개월 동안 지표 정보를 보관 (CPU, MEM 등 리소스에 대한 무료 지표 제공)
2) 로그 : 서비스나 애플리케이션, 에이전트로부터 발생되는 로그를 모니터링할 수 있습니다. Amazon S3에 저장하여 장기간 저장 및 분석을 진행하거나 VPC 흐름 로그, Route 53, ALB 액세스 로그 등을 분석할 수 있습니다.
3) 경보 : 특정 지표를 지정하여 경보를 설정하고 알림을 받을 수 있습니다. (CPU 사용률이 5분 동안 50%를 초과하는 경우 작업 트리거를 수행하게 함 - 작업 트리거는 개발 팀에 메시지를 생성하게 하거나 로그를 처리하기 위한 다른 인스턴스를 생성한다거나 등)
4) 이벤트 : AWS 리소스의 변경 상태을 알리고 자동 교정 조치를 수행합니다. (콘솔 로그인, Auto Scaling 상태 변경, EC2 인스턴스 상태 변경, EBS 볼륨 생성, 모든 API 호출)
5) 규칙 : 들어오는 이벤트에서 일치하는 것을 찾아서 대상으로 라우팅합니다.
6) 대상 : 이벤트를 처리합니다. (Amazon EC2 인스턴스, AWS Lambda 함수, Kinesis 스트림, Amazon ECS 작업, Step Function 상태 시스템, Amazon SNS 주제, Amazon SQS 대기열 및 기본 제공 대상 이 포함 될 수 있음)
최근에는 다양한 오픈소스 기반 visualize 솔루션들이 많이 나오고 있어 이와 같은 모니터링 통계 자료를 이와 연계하여 시각화 하는 방향도 검토 할 수 있습니다.
많이 들어 보신 도구로는 ELK / EFK의 K인 Kibana와 오픈소스 연계 사례가 굉장히 많으니 이후 포스팅에서 한번 구축과정을 설명하도록 하겠습니다.
Amazon CloudTrail
CloudTrail은 계정에서 이루어지는 모든 API 호출을 기록하고, 지정된 Amazon S3 버킷에 로그를 저장하는 서비스입니다.
정해진 기간 동안만 모니터링 되며, 장기적인 기간 모니터링하기 위해서는 S3에 저장해야만 합니다.
모니터링을 위한 아키텍처 예상도는 다음과 같습니다.

1) AWS Service 들은 로그 이벤트를 CloudWatch로 전송하기 위해 Trail을 구축합니다.
2) Trail은 Bucket에 로그를 저장하며 AWS KMS를 통해 데이터를 암호화 합니다.
3) Trail은 로그를 CloudWatch로 전송합니다.
4) 특정 일치 항목에 대한 로그 이벤트를 평가하기 위해 사용자 지정 CloudWatch 메트릭 필터를 정의합니다.
5) 일치가 이루어지면 CloudWatch를 구성하여 해당 알람 또는 이벤트을 트리거하고 알람을 SNS -> SES를 통해 이메일을 전송하거나 SMS 메시지를 전송합니다.
위와 같은 일련의 과정을 통해 마이크로 서비스 아키텍처에서 로깅을 분석하여 알람을 전송할 수 있는 Telemetry 환경을 구성해 보았습니다.
3. 확장성
탄력성 확보 및 아키텍처 확장
EC2의 경우 Auto Scaling Group을 사용하여 탄력성을 제공합니다. 지정된 조건에 따라 인스턴스를 시작 또는 종료하는 방식으로 여러 가용 영역에 걸쳐 시작할 수 있습니다.
자동 확장 방법으로는 예약(예측 가능한 워크로드에 적합 : 기간 또는 날짜 기반 MIN/MAX 설정), 동적(탁월한 일반 조정 : CPU 사용률 기반으로 조정), 예측(기계 학습 기반 조정) 방법이 있으며 일반적으로 동적 확장 방식을 많이 사용합니다.
Auto Scaling 그룹 지정 시 고려 사항으로는 비용에 대한 전략이 필요하고, 여러 유형의 autoscaling을 통합해야 하는 경우를 판단해야 하며, 스케일 인 / 아웃에 대한 단계 조정 (한번에 하나씩 또는 여러개에 대한 증가 감소 치 결정), 스케일 아웃은 미리미리 확보가 되도록 해야하며, 스케일 인 정책은 느리게 감소되도록 하는 것이 좋으니 (너무 민감하게 1분 측정치를 기준으로 측정하지 않도록 하는것이 좋음. 최소 5분에서 30분 이상의 시간을 측정) 이와 같은 고려 사항을 기반으로 EC2의 탄력성을 확보할 수 있는 아키텍처를 설계하는 것이 중요합니다.
4. 데이터베이스 규모 조정
데이터베이스는 크게 Scale-Out (수평적 확장) / Scale-Up (수직적 확장)으로 나눠 생각할 수 있습니다.
이중 읽기 전용 복제본으로 수평적 규모조정을 수행할 수 있는 Amazon RDS가 있으며, 마스터 서버로 쓰기를 처리하고 복제는 비동기식으로 동작합니다.
또한 일반 데이터베이스를 수직적으로 확장 또는 축소할 수 있는 Scalie-Up / Scale-Down 방식을 적용할 수 있습니다. 다만 수직적 확장의 경우 다운타임이 발생할 수 있다는 치명적인 단점이 발생할 수 있습니다.
다만 복제본을 미리 만들고 기동이 또 다른 인스턴스 환경에서 완료된 이후 기존 서비스를 다운하는 가동 중단 시간 없이 수직적으로 확장이 가능하기도 하지만, 이는 비용적인 문제를 고려해야 합니다.
Aurora DB 클러스터
Aurora DB의 경우 Master 인스턴스에서 읽기 쓰기 작업을 진행하고 클러스터 볼륨의 복제본을 통해 또 다른 가용영역으로 복제되는 방식입니다.
Aurora DB 복제본은 읽기 작업만 지원하며 최대 15개까지 사용이 가능합니다.
Aurora 서버리스
Lambda 형식으로도 제공하며 애플리케이션에 자동으로 응답하고 ACU 수 사용에 따라 비용을 지불합니다.
예측할 수 없는 단기 워크로드에 적합한 방식입니다.
데이터베이스 샤딩으로 Amazon RDS 쓰기 조정
- 샤딩은 데이터를 큰 청크(샤드)로 분할합니다.
하나의 데이터베이스에서 성이 A~M일 경우 첫번째 샤드에 나머지는 두번째 샤드에 저장하도록 하는 방식입니다.
Scale-In / Out은 아니지만 멀티 데이터베이스로 쓰기를 분산시킬 수 있습니다.
이로인한 보다 뛰어난 성능과 운영 효율성을 기대할 수 있습니다.
DynamoDB의 두가지 조정
- Auto Scaling 방식 : 상한과 하한 경계를 지정 (대부분의 애플리케이션에 적합)
- 온디맨드 방식 : 프로비저닝 없이 구성
- 파티션을 구분하여 저장할 때 핫 키로 좋은 예로는 사용자 ID, 디바이스 ID(유니크한 정보) 등이 있고, 나쁜 예로는 상태 코드, 항목 생성 날짜 등이 있음 (중복 되는 정보)
이론적인 내용은 여기까지 살펴보고 이제 고가용성 환경에 대한 아키텍처를 살펴보겠습니다.
다양한 부분의 고가용성 아키텍처 고려사항을 반영한 도식화 된 예상 이미지는 다음과 같습니다.
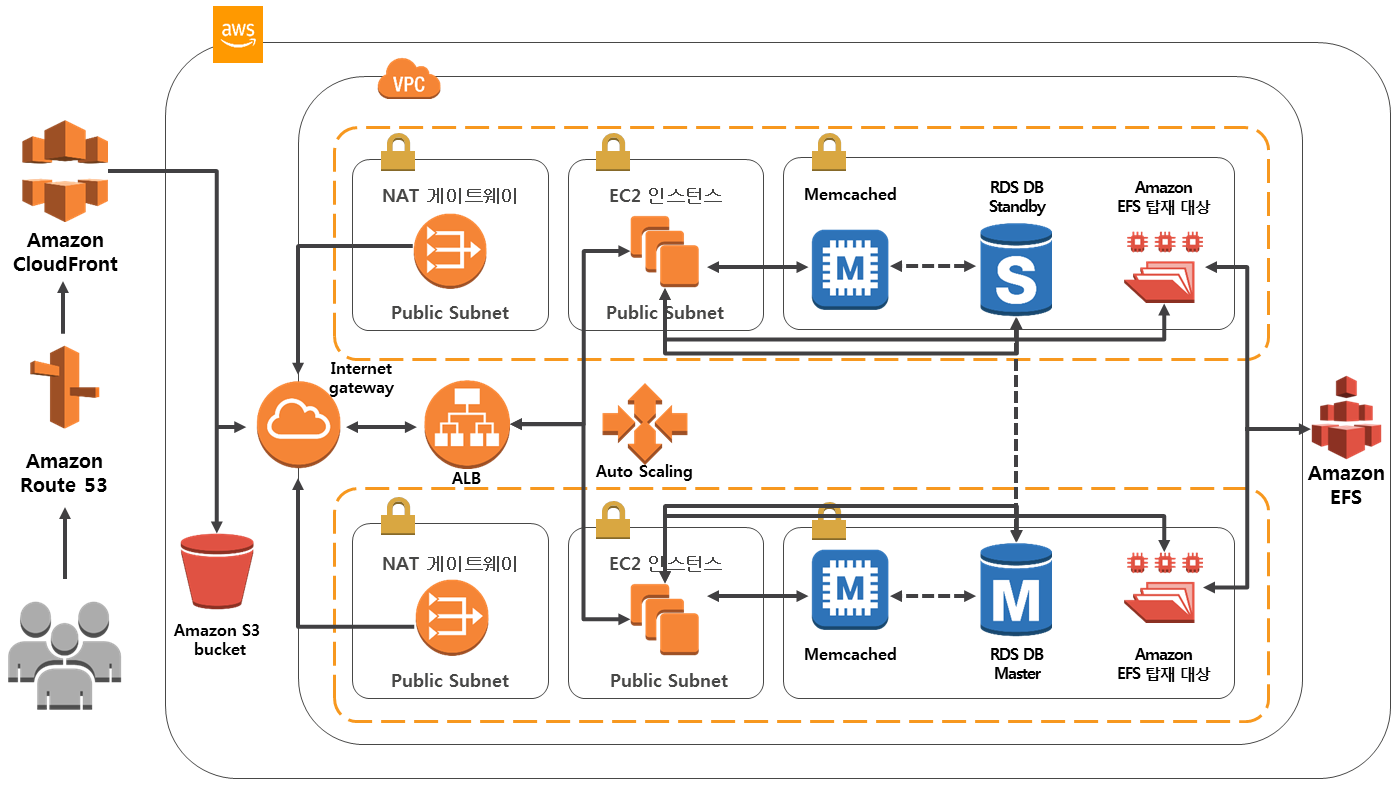
1) 클라이언트는 Amazon Route 53을 통해 Multi-Region 또는 Multi-AZ에 분산되어 있는 Host를 찾아간다.
2) 이때 먼저 Amazon CloudFront를 통해 CDN 서비스를 제공받는다.
3) 정적자원을 요청할 경우 Amazon S3를 통해 전달 받고 캐시 데이터의 경우 CloudFront에 저장 또는 직접 전달받는다.
4) 동적자원의 경우 Internet Gateway를 통해 Application Load Balancer로 전달하며, 가용성을 위한 이중화 또는 다중화 로드 밸런싱을 수행한다. 이때 대상은 퍼블릭 서브넷에 존재하는 웹 서버 인스턴스이며 오토 스케일링 그룹으로 확장성을 보장한다.
5) 웹 서버는 데이터 존에 위치하는 RDS DB에 접근하며, RDS DB는 기본 Master & Standby로 이중화 구성하고 서로 간에 미러링을 통해 원본을 유지한다. 이때 Standby 서버를 Read Only로 사용할 수 있다.
6) 초고속 데이터 접근을 위한 Memcached를 사용하여 RDS에서 자주 검색되는 데이터를 저장하여 빠른 응답을 기대할 수 있다.
7) 파일 접근을 위한 Amazon EFS 탑재 대상을 통해 EFS에 접근하여 파일을 전송 받는다.
8) Private Subnet에서 OS 업데이트 또는 아웃바운드 트래픽을 통해 인터넷에 연결해야 할 경우에는 NAT 게이트웨이를 통해 Internet Gateway에 접근한다.
고가용성 아키텍처를 제공하는 방법은 이외에도 다양합니다.
다만 고가용성을 확보하기 위한 정책들은 대부분 비용을 수반하기에 사이트에 맞는 설계가 반드시 필요합니다.
'③ 클라우드 > ⓐ AWS' 카테고리의 다른 글
| Amazon EKS 30분만에 구성하기 (CloudFormation) (7) | 2020.10.10 |
|---|---|
| Micro Service와 Serverless (0) | 2019.07.09 |
| AWS IAM (Identity and Access Management) (0) | 2019.07.07 |
| ELB, Amazon Route 53, Amazon 네트워킹 (VPC 피어링, VPC 엔드포인트) (0) | 2019.07.07 |
| Amazon VPC (Virtual Private Cloud), VPC Peering (0) | 2019.07.07 |
- Total
- Today
- Yesterday
- git
- JEUS7
- Da
- MSA
- node.js
- aa
- API Gateway
- OpenStack
- 쿠버네티스
- SWA
- 오픈스택
- aws
- 마이크로서비스 아키텍처
- webtob
- k8s
- JEUS6
- openstack token issue
- 아키텍처
- Docker
- nodejs
- apache
- Architecture
- TA
- kubernetes
- jeus
- 마이크로서비스
- openstack tenant
- SA
- JBoss
- wildfly
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |