
티스토리 뷰
이번 시간에는 AWS의 대표적인 Storage Service인 S3에 대해 살펴보겠습니다.
S3는 가장 간단한 형태로 클라우드 서비스에 서비스를 제공할 수 있으며, 안정적으로 데이터를 배포, 저장, 분석하는 방법을 제공합니다.
# 본 포스팅은 개인적으로 또는 회사 차원에서 진행한 TF의 다양한 학습 결과 그리고 Architecting On AWS 교육 등을 통해 습득한 지식을 리마인드하며 공유하는 것임을 알려드립니다.
S3를 살펴보기에 앞서 우리가 아키텍처를 설계할 때 고민해야할 중요한 포인트가 있습니다. 바로 AWS가 제공하는 다양한 서비스들이 위치할 Scope을 정의하는 것인데, S3는 대표적인 리전 서비스 영역입니다.

자 그럼 AWS의 Scope은 어떻게 구분되는지 살펴봐야겠죠?
AWS Service Scope
1) AWS 데이터 센터
- 콜드 연결이 아닌 온라인으로 연결되어 있다.
- 다양한 ODM을 사용하며 사용자 지정 네트워크 프로토콜 스택을 지원
- 하나의 데이터 센터는 하나의 AZ에 포함 됨
2) AWS 가용 영역 (AWS AZ) 66개
- 하나 이상의 데이터 센터로 구성
- 내결함성을 갖도록 설계
- 프라이빗 링크를 통해 다른 가용 영역과 상호 연결
- VPC를 구성할 때 가용 영역을 지정하여 사용할 수 있음 (1개 또는 그 이상)
- 한국 리전에는 3개의 AZ가 존재함 / 이를 통해 AZ간 장애 복구를 수행할 수 있음
3) AWS 리전 21개 (서울 리전 3개의 가용 영역)
- AWS 리전은 두 개 이상의 가용 영역으로 이루어짐
- 현재 21개의 리전을 갖고 있음
- 리전 전체에서 데이터 복제를 적용 및 제어할 수 있음
- 리전 간 통신은 AWS 백본 네트워크 인프라를 사용
4) AWS 글로벌 인프라
- End-user에게 빠른 응답 시간을 보장하기 위해 엣지 로케이션을 지원
- CDN 서비스를 통해 오리진 서버로 부터 직접 데이터를 가져올 필요 없이 빠른 호출이 가능하도록 대안을 제시
- 방화벽이나 DNS 서비스 등 역시 엣지 로케이션에서 지원
- AWS 엣지 로케이션 (Amazon CloudFront, Amazon Route 53, AWS Firewall Manager, AWS Shield 및 AWS WAF 서비스)
- CDN 서비스(AWS CloudFront 서비스) 제공 영역
AWS Scope이 결정되면 AWS 아키텍처를 설계할 수 있는 밑그림을 그릴 수 있게 됩니다.
크게 서비스의 범주와 AWS VPC 영역에 포함되는지 여부를 판단하고 전체적인 아키텍처를 그리게 되는데, VPC는 차차 알아보도록 할 예정이니 미리 겁먹지 마시고 아래를 기반으로 아키텍처의 밑그림을 그려보시기 바랍니다.
1) Service Scope을 이해해야 한다.
- 글로벌 서비스 : 엣지 로케이션 서비스 (Amazon CloudFront, Amazon Route 53, AWS Firewall Manager, AWS Shield 및 AWS WAF 서비스), IAM 서비스, STS 서비스 등
- 리전 서비스 : S3 서비스, VPC 서비스, EFS 서비스 (NAS 서비스와 비슷한 용도, 공유 볼륨) 등
- 가용 영역 서비스 : EC2 서비스, RDB 서비스, EBS 서비스(볼륨 서비스 / 디스크 추가), Route Table 서비스, 서브넷 서비스 등
2) VPC 기반 서비스 인지 아닌지
- NON VPC 기반 : S3 서비스 등
- VPC 기반 : NAT 서비스, ELB 서비스, EC2 서비스 등
최종적으로 우리는 어마어마한 아키텍처를 도출해 낼 것입니다. 아니 그건 시작점 정도가 될 수도 때론 그 사이트의 이상적인 아키텍처가 될수도 있습니다.
Amazon S3
Amazon S3는 앞서 살펴본봐와 같이 리전 레벨의 서비스입니다. 따라서 S3는 AZ 영역 외부에 아키텍처가 위치하게 됩니다.
Amazon S3의 대표적인 특징으로는 객체 수준의 스토리지를 제공한다는 것입니다.
여기서 살펴봐야 할 부분은 스토리지의 유형입니다.
스토리지의 서비스 유형 3가지 (클라이언트에서 접근하는 방식이 다르다.)
- 오브젝트(파일 + 메타데이터) 기반 스토리지 (S3, Ceph) : RESTFul API로 접근이 가능(http protocol의 메소드를 사용하여 C(POST)R(GET)U(PUT)D(DELETE) 오퍼레이션이 가능하다.)
- 블록 기반 스토리지 (EBS, SAN, iSCSI) : EC2에 장치 파일 형태로 붙어서 사용 (/dev/xvda, xvdb.. xvdn), 디스크를 운영팀에서 용도별로 포맷해서 사용해야 함
- 파일 기반 스토리지 (EFS, Ceph, NAS, NFS) : 디렉토리로 마운트해서 사용하는 방식
- 공유와 업데이트 측면에서 살펴봤을 때에는 공유는 오브젝트 스토리지 / 업데이트는 블록과 파일 스토리
| 오브젝트 스토리지 | 블록 스토리지 | 파일 스토리지 | |
| 공유 | O | X | O |
| 업데이트 | X | O | O |
| 비용 | 저렴 | 중간 | 비쌈 |
즉 Amazon S3는 객체 레벨의 RestFul API로 접근이 가능하며, CRUD를 http protocol을 통해 수행할 수 있다는 특징이 있습니다.
또한 기본 3copy 복제본을 만들어 유지하기 때문에 99.999999999%(eleven nines %) 내구성을 제공하며, 특정 이벤트 또는 Lambda Function을 통해 트리거 시킬 수 있습니다.
마지막으로 스토리지 클래스 분석을 통해 비용 최적화를 수행할 수 있습니다.
최초 Amazon S3에 저장된 데이터를 액세스 빈도가 낮을 경우 Amazon S3 Standard-Infrequent Access(Amazon S3 IA)로 이전하여 비용 최적화를 자동으로 식별해 줍니다.
Amazon S3가 사용 기반 비용을 Charge하다보니 비용에 대한 고려는 매우 중요합니다.
Amazon S3로 업로드를 하거나, Amazon S3에서 CloudFount(엣지 로케이션) 또는 EC2로 전송하는 경우에는 별다른 비용이 발생하지는 않지만, 사용량 기반 / CRUD 요청 기반 / 다른 리전 또는 인터넷으로 전송 할 경우 비용에 대한 차지가 발생하니 각별히 권한 부여에 주의를 기울여야 합니다.
Amazon S3 사용 사례
위와 같은 특징을 기반으로 Amazon S3를 어떠한 경우에 적용하여 설계하는 것이 좋을까 사례를 살펴보도록 하겠습니다.
먼저 정적 웹 콘텐츠 및 미디어 저장 및 배포 용도입니다. 가장 일반적인 방식으로 정적 컨텐츠를 S3 버킷에 저장하여 리전레벨에서 보다 빠르게 접근할 수 있도록 구성합니다.
최초 생성된 S3 버킷의 경우 생성자 이외에는 모두 접근이 불가능하며, 이를 Public으로 공개하거나 특정 사용자에게 권한을 부여하여 접근할 수 있도록 오픈하는 정책을 적용할 수 있습니다.
여기서 유의할 점은 S3 Name은 리전 Scope이나, S3 Bucket Name은 글로벌 Scope을 갖습니다. 즉 글로벌 레벨에서 동일한 bucket name을 생성할 수 없다는 것입니다.
예를들어 아래와 같이 nrson이라는 bucket name은 전 세계에 유일해야 합니다.
- https://[resion name].amazonaws.com/[bucket name]/
- https://s3-ap-northeast-2.amazonaws.com/[bucket name]/
- https://s3-ap-northeast-2.amazonaws.com/nrson/nrson.png
{kind=link}
다음으로 버전 관리 용도입니다.
버킷을 통해 실수로 삭제하거나 덮어쓴 객체를 복구할 수 있습니다. 아마도 Docker Image 버전 관리 방식과 매우 유사합니다.
이전 버전에 대한 DELETE, UPDATE 이전 버전을 관리를 할 수 있으며, 동일 Resource Name의 경우 사진의 이름이 같더라도 리소스 id가 변경되면서 이전 버전의 사진으로 롤백할 수도 있습니다.
당연히 저장이 배수로 늘어나 추가적인 스토리지 사용으로 인한 비용 차지가 발생할 수 있습니다.
다음으로 CORS (Cross Origin Resource Sharing)를 통한 액세스 제어입니다.
하나의 도메인에서 다른 도메인의 S3 버킷에 접속하여 사용할 수 있도록 하는 설정입니다.
다음으로 대용량 분석 또는 연산을 위한 데이터 스토어 역할입니다.
S3의 사용량을 분석하거나, 거래 분석, 클릭스트림, 미디어 트랜스코딩 등의 분석 기능으로 사용할 수 있습니다.
마지막으로 백업 및 아카이빙 도구로서의 Amazon S3입니다.
내구성 및 확장성이 매우 뛰어난 스토리지 서비스로 장기적으로 필요한 데이터의 경우 Amazon S3 Glacier로 이전하여 관리하면 비용적인 이점을 가져갈 수 있습니다.
EC2, EBS 등의 스냅샷을 저장하는 공간도 Amazon S3임을 기억합니다.
위와 같은 사례를 기반으로 다음과 같은 경우 Amazon S3를 적용하면 좋을 듯 합니다.
[Best Case]
- 한번 쓰고 여러 번 읽어야 하는 경우 (오브젝트 단위 / 한번 업로드하고 여러번 다운로드 할 때 / 공유할 때)
- 데이터 액세스가 일시적으로 급증하는 경우
- 사용자가 매우 많고 콘텐츠 양이 다양 할 때
- 데이터 세트가 계속 증가 할 때
[Worst Case]
- 블록 스토리지 요구 사항 (EC2의 디렉토리가 더 필요한데 S3로 사용하려고 하는 경우)
- 자주 바뀌는 데이터에 대한 경우 (업데이트가 빈번하게 발생하는 경우)에는 오브젝트 스토리지 보다 블록 스토리지 및 파일 스토리지가 어울림
- 장기 아카이브 스토리지가 필요한 경우 (비용이 비쌈. Amazon Glacier 권고)
Amazon S3 데이터 전송 방식
앞서 살펴본 봐와 같이 Amazon S3는 오브젝트 스토리지 일종으로 RestFul API로 접근이 가능합니다.
실제로 데이터를 전송하는 다양한 방법은 다음과 같습니다.
1) 클라이언트 환경에서 CLI, AWS WebConsole, API를 통한 전송 방식
2) AWS DataSync를 통한 온 프레미스 스토리지와 Amazon S3 또는 Amazon EFS 간의 데이터 이전 방식
3) 완전 관리형 서비스인 AWS Transfer for SFTP를 통한 애플리케이션 to Amazon S3 서비스
4) 멀티파트 업로드의 경우 분할하여 병렬로 동시에 전송이 가능한 구조로 업로드 속도를 향상 시키고 업로드가 완료되면 Amazon S3 내부에서 멀티파트 업로드 파일을 조립하여 객체를 다시 생성하는 방식을 취합니다.
멀티파트 업로드의 경우 분할 업로드 방식을 취해 네트워크 단절에 대한 재전송의 위험 최소화, 객체 생성과 동시에 전송 가능, 속도의 향상 등에 대한 이점을 함께 가져갈 수 있습니다.
5) 엣지 로케이션을 통한 전송 방식을 통해 AWS 엣지 로케이션에 위치한 CDN을 통해 업로드가 되어 보다 빠른 업로드 가능합니다.
# 참고
Amazon S3 Transfer Acceleration Tool을 통한 업로드 속도 비교
http://s3-accelerate-speedtest.s3-accelerate.amazonaws.com/en/accelerate-speed-comparsion.html
http://s3-accelerate-speedtest.s3-accelerate.amazonaws.com/en/accelerate-speed-comparsion.html
s3-accelerate-speedtest.s3-accelerate.amazonaws.com
위 사이트를 통해 현 리전 기준 Amazon S3 버킷에 업로드 할 경우의 속도 비교를 측정해 볼 수 있습니다.
현재 시간 2019년 7월 7일 00시 08분 기준 업로드 측정 결과입니다.
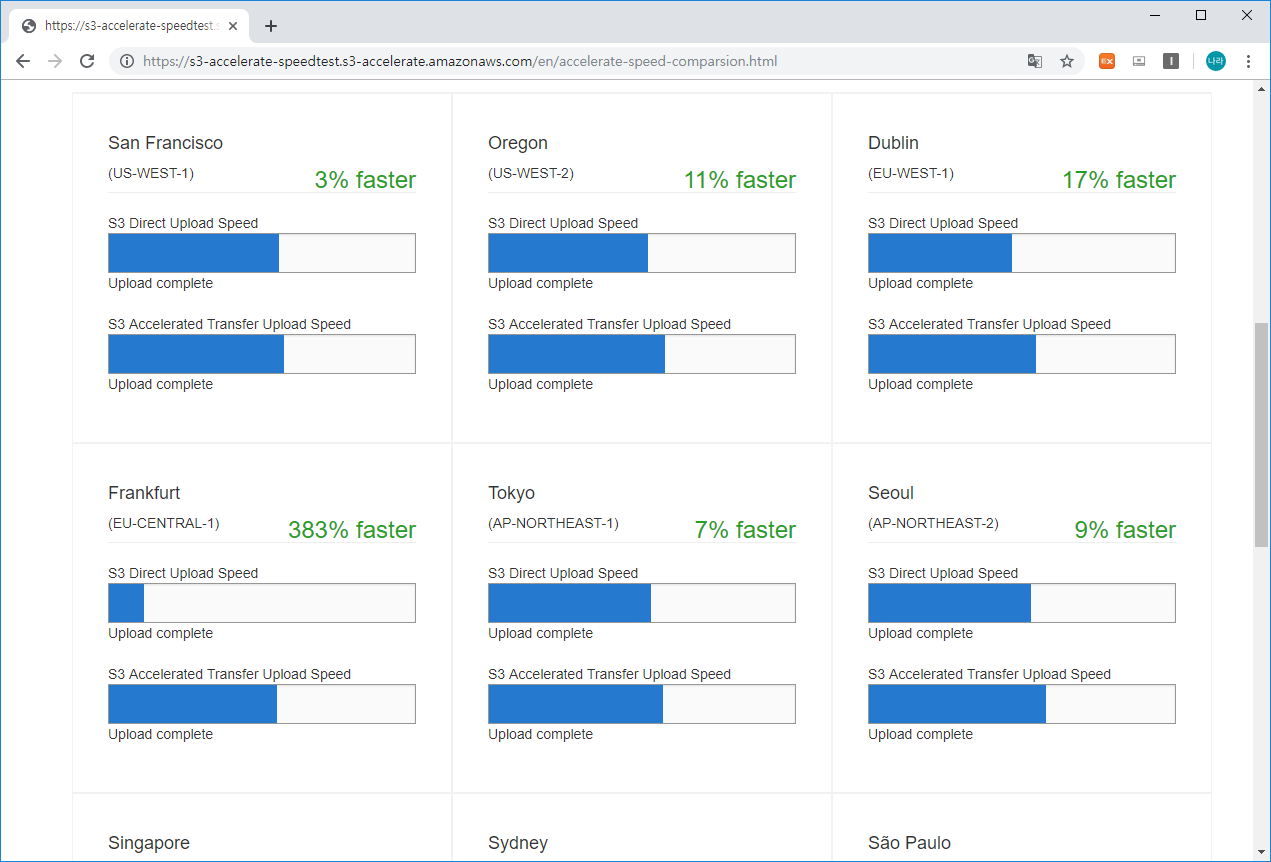
현재 기준 Seoul의 경우 인터넷을 통해 직접 업로드 하는 것과 엣지 로케이션 (AWS CloudFront)을 통해 전송하는 것이 9% 정도 빠른 속도를 나타내고 있습니다.
보시는 것처럼 대부분의 사이트가 엣지 로케이션 (AWS CloudFront)를 통해 전송하는 것이 더 빠르며, 특히 프랑크푸르트의 경우 383% 더 빠르다는 결과가 나왔네요. 서울은 원래 인터넷 자체도 매우 빨라서 그렇게 큰 효과가 보이는 것 같지는 않지만 9% 빠른것도 꽤 차이가 난다고 볼 수 있습니다.
6) AWS Snowball을 통한 페타데이터 규모의 데이터 전송 (오프라인 방식 업로드)
7) AWS Snowmobile을 통한 엑사바이트 규모의 데이터 전송 (오프라인 방식 업로드)
Amazon S3 Glacier
앞서 살펴본 몇가지 비용 절감 정책 중 Amazon S3 -> Amazon S3-IA -> Amazon Glacier로 수명 정책을 자동으로 지정하는 것이 중요하다고 설명했습니다. 이는 각 스토리지 별로 자주 사용되는지 여부를 검증하여 보다 저렴하지만 안좋은 스토리지로 이동하게 하는 정책인데 특히 Amazon S3 Glacier의 경우 가장 저렴한 스토리지 비용으로 장기 데이터 스토리지 역할을 수행합니다.

- 장기 데이터 스토리지
- 아카이브 또는 백업
- 매우 저렴한 스토리지
- Audit Log 등을 백업하는 역할로 사용할 수 있음
- S3는 메타데이터가 결합된 오브젝트 형태로 버킷 생성
- Glacier는 오브젝트 형태로 Vault를 생성하여 CLI로 아카이브 단위로 Read-Only로 저장
Amazon S3 Glacier 비용 정책으로는 검색 시간을 기준으로 비용을 측정하게 됩니다. 안타깝게도 Glacier의 치명적인 단점은 검색 시 기본 수시간이 걸릴 수 있다는 점인데, 이를 다음과 같은 정책으로 변경할 수 있습니다.
- 신속 검색 (1~5분 이내) 비싸다
- 표준 검색 (3~5시간 이내) 표준
- 대량 검색 (5~12시간 이내) 싸다
좀 더 세분화 하자면 S3 Standard -> S3 Standard IA -> S3 One Zone IA -> S3 Glacier/Deep 아카이브 순으로 저렴해지지만 굳이 하나를 선택하여 사용할 필요는 없습니다. 최근 Amazon S3 지능형 계층화 서비스가 등장하여 두개 이상의 스토리지를 지정하여, 지능형으로 자동으로 관리되는 설정할 수 있습니다.
대표적으로 음원이 이런 경우가 많은데 예전 음원이 최근 ost로 등장하여 갑자기 엑세스가 늘어났을 경우 상위 레벨로 변경되었다가 다시 엑세스가 안되면 내리고 이런식으로 스스로 체크해 주는 방식입니다. 대표적인게 벗꽃엔딩.. 봄만되면.. 올라가고 내려가고.. 아시죠? 봄이 되어 자주 액세스 되면 One Zone에서 Standard 자동으로 복제한다던지의 관리가 자동으로 관리됩니다.
Amazon S3 구성하기
자 그럼 본격적인 실습을 진행해 보도록 하겠습니다.
Amazon S3만 구축하면 되기 때문에 어렵지 않게 웹상에 개인 공간을 오픈할 수 있습니다.
1. Amazon S3 버킷 생성
1) AWS Management Console의 Services 메뉴에서 S3 선택
2) Create bucket(버킷 만들기) 클릭
3) 버킷 만들기 -> Bucket name 지정
- 버킷은 앞서 살펴본 것처럼 글로벌 Scope을 갖고 있어 이미 생성되어 있는 버킷은 만들수가 없습니다.
- 저는 제 이니셜인 nrson으로 버킷을 생성하겠습니다.

4) 옵션구성
- 버전 관리, 서버 액세스 구성, 태그, 객체 수준 로깅, 기본 암호화, CloudWatch 모니터링 등의 기능을 추가로 구성할 수 있습니다.

5) 권한 설정
- 권한 설정은 기본으로 모든 퍼블릭 액세스 차단으로 되어 있습니다.
- 테스트를 위해 해당 옵션을 끄고 버킷을 생성합니다.
6) 버킷 확인

2. 버킷 설정
1) 버킷 이름(nrson) 클릭 -> 속성 (Properties) -> 정적 웹 사이트 호스팅 (Static website hosting) 클릭
- 화면에 보이는 엔드포인트를 클릭하거나 복사하여 호출을 시도해 봅니다.
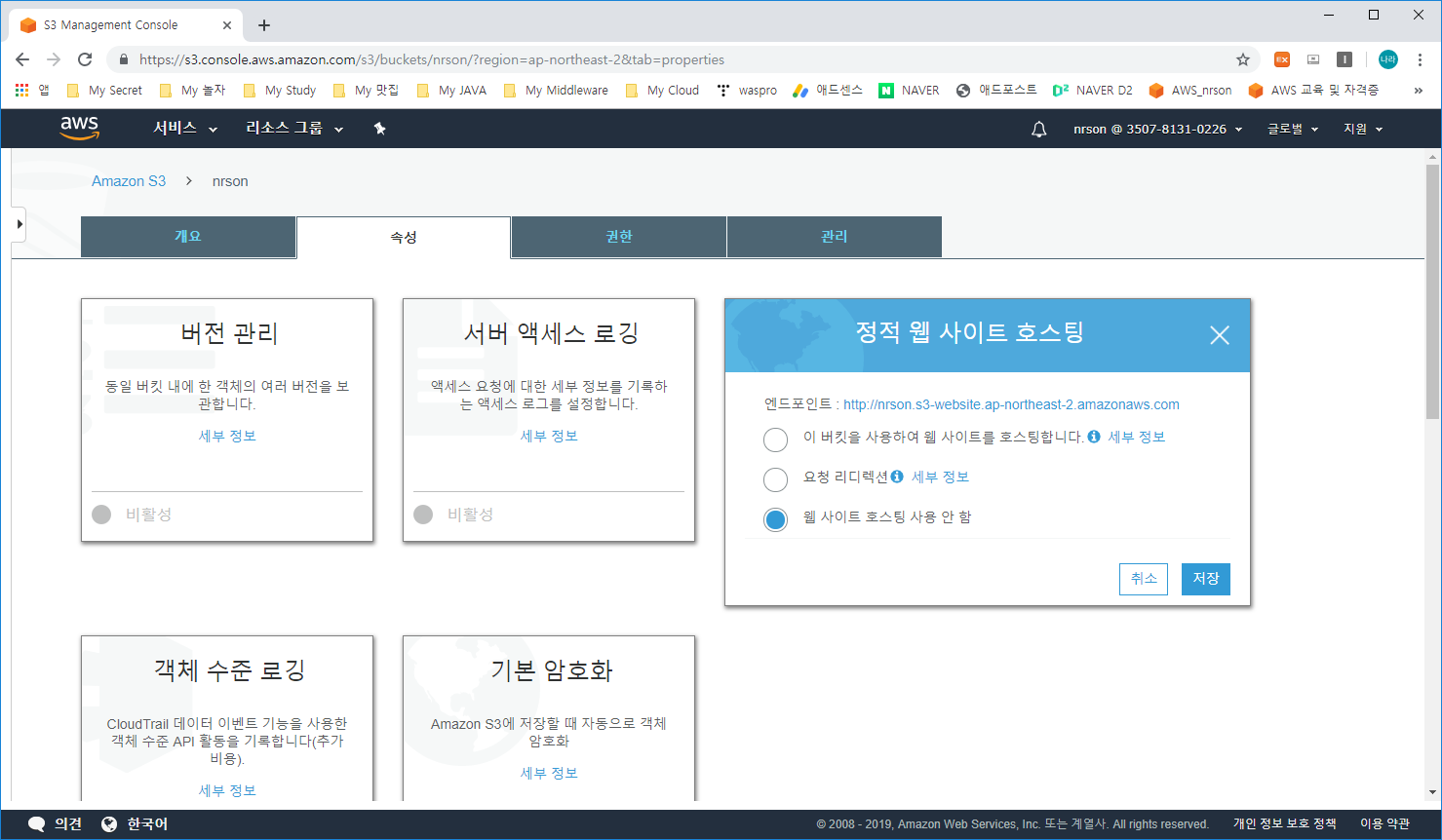
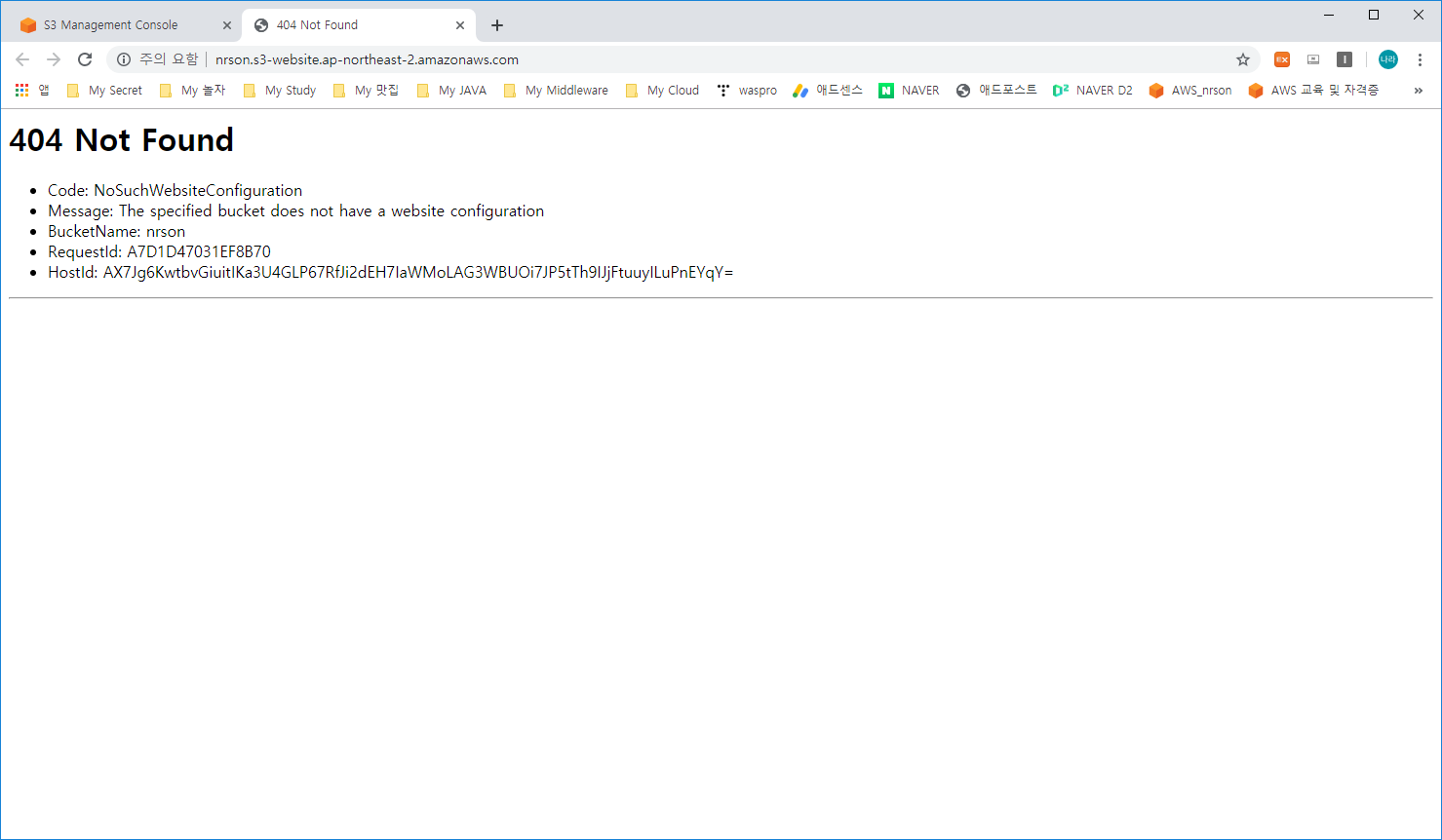
결과는 당연히 404 Not Found가 발생할 것입니다.
2) 정적 웹 사이트 호스팅 설정 변경
- 먼저 "웹 사이트 호스팅 사용 안 함"에서 "이 버킷을 사용하여 웹 사이트를 호스팅합니다."를 선택하고 인덱스 문서에 hello.html을 입력하고 저장합니다.

3) 파일 업로드
- 호스팅 할 준비가 완료되었으니 파일을 업로드 해보도록 하겠습니다.
- Amazon S3 -> nrson 버킷 -> 개요 -> 업로드 선택
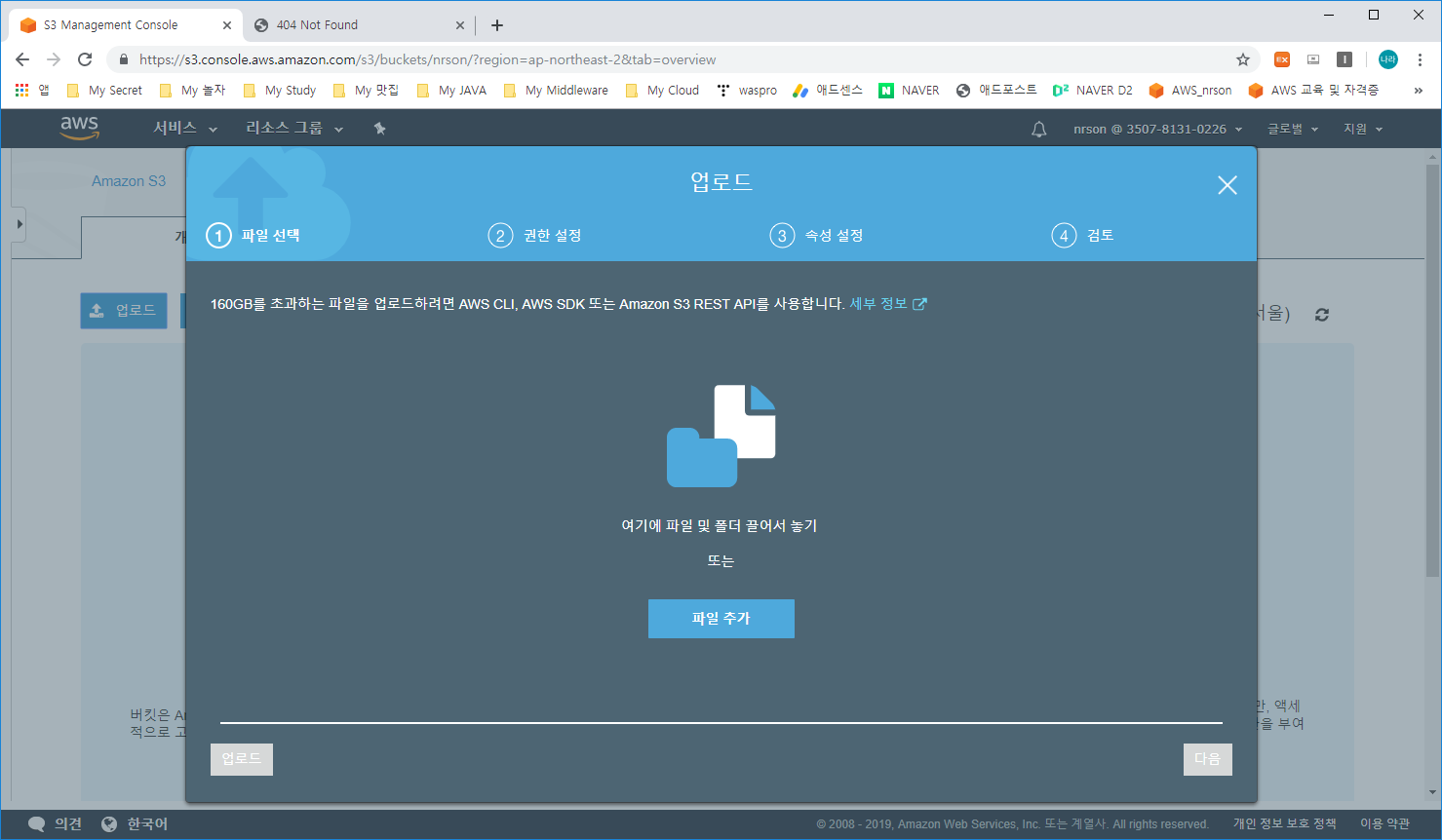
4) 파일 추가
- 호스팅할 파일을 업로드합니다.
5) 현재 상태로 호출을 수행해 봅니다.
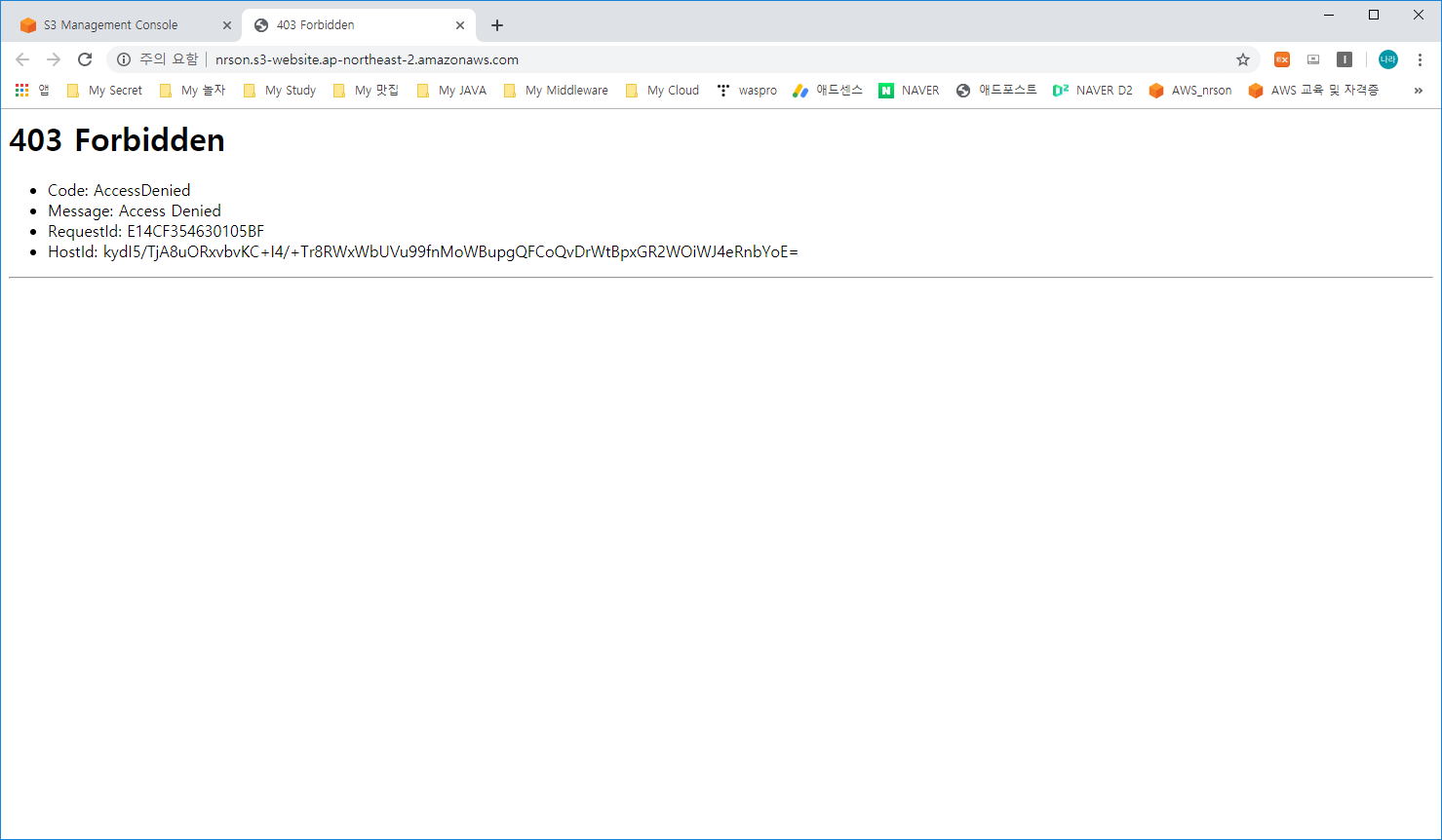
기존이랑 다르게 403 Forbidden 상태로 변경된 것을 볼 수 있습니다.
hello.html이라는 index 파일이 업로드 되어 파일의 존재 여부가 확인되어 404 Not Found는 발생하지 않았으나, 접근 권한에 문제가 발생하여 403이 발생한 것을 알 수 있습니다.
3. 접근 권한 설정
1) 퍼블릭으로 공개 설정
먼저 업로드한 개체를 선택하고 작업 -> 퍼블릭으로 설정을 선택


2) 페이지 확인
- 자 마지막으로 확인해 보면 다음과 같이 호출이 되는 것을 볼 수 있습니다.

과정을 한번 되짚어보자면,
1. Amazon S3 버킷 생성
2. 버킷 활성화 및 파일 업로드
3. 업로드 파일 활성화
클릭 몇번 만으로 손쉽게 인터넷 공간에 파일을 업로드 하고 공개할 수 있게 되었습니다. 어디서든 손쉽게 접근이 가능하며 지금은 다루지는 않았지만, Amazon Route 53이라는 DNS 서비스를 통해 정형화 되어 있지 않은 Domain을 나만의 도메인으로 변형할 수 있습니다. 물론.. 돈이 듭니다.
자 실습까지 진행해 보았는데, 사실 이상태로 공개된 파일을 웹상에 두면, 누군가의 공격을 받을수도 있어요. 그러다 보면 저도 모르는 사이에 과금이 어마무시하게 쌓일 수 있으니, 이후 방어 정책이 적용되기 전까지는 실습을 진행하시고 나서 꼭 지우는 습관을 갖도록 하는게 중요합니다.
과금 정말 무섭습니다.. 저도 첨에 수십 달러 날린 기억이 있어서.. ㅠ.ㅠ
그럼 이번 시간에는 Amazon S3를 활용한 아키텍처 설계 과정 및 실습을 진행하였습니다.
다음시간에는 컴퓨팅 계층 구조에 대해 살펴보도록 하겠습니다.
'③ 클라우드 > ⓐ AWS' 카테고리의 다른 글
| Amazon RDS (Relational Database Service), Amazon DynamoDB 그리고 AWS DMS (Database Migration Service) (0) | 2019.07.07 |
|---|---|
| Amazon EC2(Elastic Compute Cloud), EBS(Elastic Block Store), Amazon EFS 및 Amazon FSx (0) | 2019.07.07 |
| AWS WAF(Well-Architecture Framework) (0) | 2019.07.06 |
| AWS Architecturing (0) | 2019.07.06 |
| AWS(Amazon Web Servces)에서 제공하는 서비스 종류와 역할 (1) | 2019.03.31 |
- Total
- Today
- Yesterday
- JEUS7
- 마이크로서비스 아키텍처
- jeus
- Architecture
- 오픈스택
- Docker
- API Gateway
- SA
- 마이크로서비스
- k8s
- MSA
- aa
- Da
- TA
- JBoss
- SWA
- wildfly
- kubernetes
- nodejs
- apache
- openstack tenant
- JEUS6
- webtob
- 쿠버네티스
- node.js
- openstack token issue
- aws
- 아키텍처
- git
- OpenStack
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |